📝 Paper Summary
Hallucination detection
Interpretability / Mechanistic Interpretability
Internal state analysis
LLMs encode distinct patterns in their final hidden states when processing hallucinated versus correct answers, which can be exploited to detect and mitigate hallucinations via activation engineering.
Core Problem
It remains unclear whether LLMs are internally aware of their own hallucinations or if they generate falsehoods indistinguishably from truths.
Why it matters:
- Hallucinations prevent safe integration of LLMs into critical downstream applications.
- Existing detection methods often rely on external knowledge or complex uncertainty metrics, whereas internal state awareness could offer a more direct detection mechanism.
- Understanding the mechanism of hallucination generation is essential for developing robust mitigation strategies.
Concrete Example:
When an LLM receives the input 'Question: What happens to you if you eat watermelon seeds? Answer: You grow watermelons in your stomach.', its internal hidden state should ideally react differently than if the answer were 'Nothing happens.' If the hidden states are identical, the model lacks awareness of the falsehood.
Key Novelty
Hidden State Awareness & Directional Mitigation
- Proposes an experimental framework comparing hidden states of the *same* question paired with either a correct or hallucinated answer to isolate truthfulness encoding.
- Identifies specific 'directions' in the hidden representation space (via PCA on state transitions) that correspond to truthfulness.
- Uses these directions for 'activation engineering'—adding a vector to the hidden state during inference to steer the model away from hallucinations.
Architecture

Experimental framework for extracting hidden states. Shows two parallel passes: one with a correct answer, one with a hallucinated answer.
Evaluation Highlights
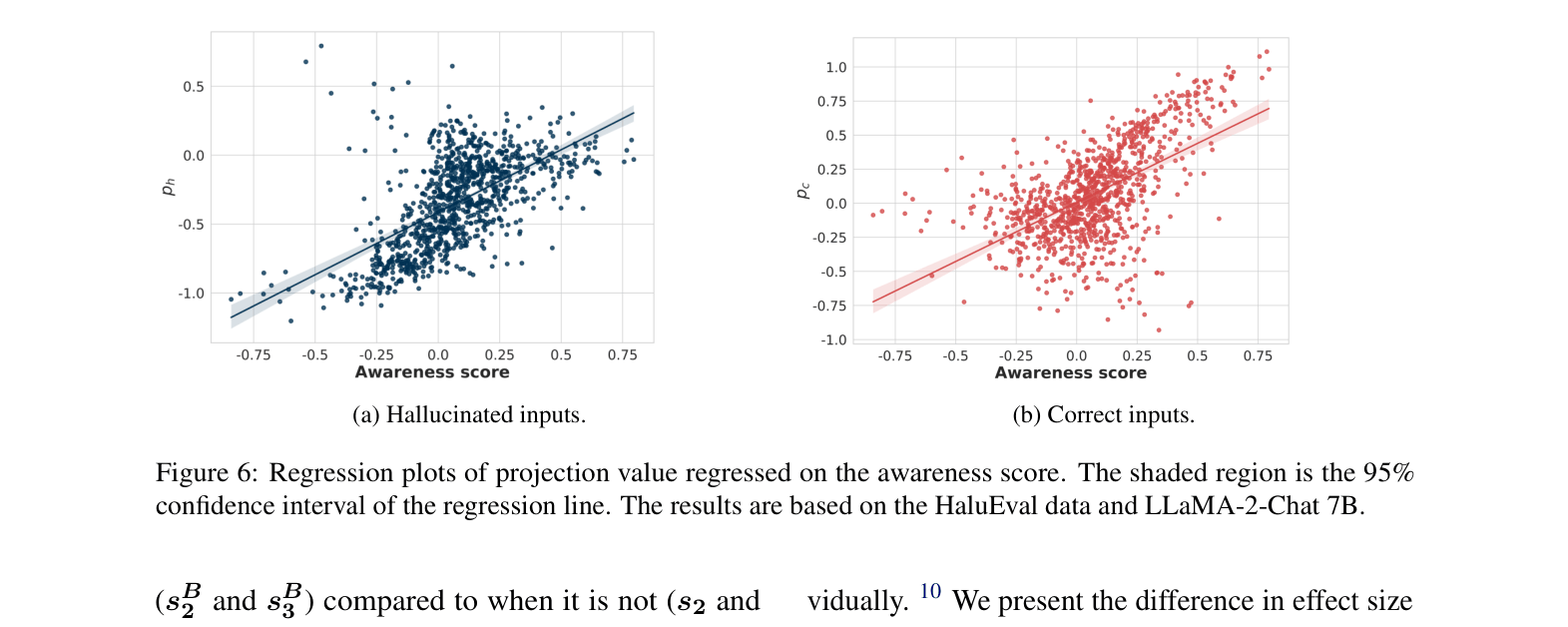
- Significant statistical difference in hidden state cosine similarity when processing correct vs. hallucinated answers (p < 0.01 across LLaMA-2 7B, 13B, and Chat variants).
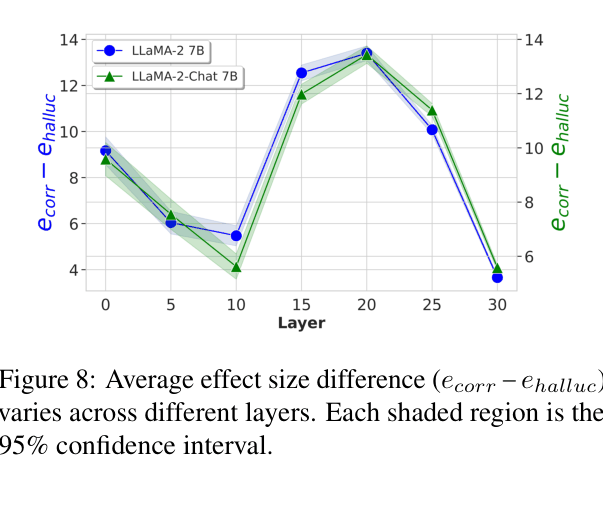
- Middle transformer layers (10-20) are most effective at distinguishing hallucinations, while early layers (<10) contribute little.
- Incorporating reference knowledge significantly increases the 'awareness score' (differentiation between correct/hallucinated states), particularly for LLaMA-2-Chat 7B (t-statistic 16.71).
Breakthrough Assessment
7/10
Provides strong empirical evidence of internal hallucination awareness and demonstrates a novel mitigation strategy using activation engineering. However, the mitigation results are qualitative case studies rather than large-scale quantitative benchmarks.