📊 Experiments & Results
Evaluation Setup
Binary classification of hallucinations on the RealHall benchmark suite
Benchmarks:
- RealHall Closed (Closed-domain consistency checking) [New]
- RealHall Open (Open-domain factuality checking) [New]
Metrics:
- AUROC
- Statistical methodology: Head-to-head comparison averaged across datasets
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| ChainPoll demonstrates superior aggregate performance across all RealHall benchmarks compared to baselines. | ||||
| RealHall (Aggregate) | AUROC | 0.673 | 0.781 | +0.108 |
| RealHall Open | AUROC | 0.670 | 0.772 | +0.102 |
| RealHall Closed | AUROC | 0.593 | 0.789 | +0.196 |
| RealHall Closed | AUROC | 0.584 | 0.789 | +0.205 |
Experiment Figures
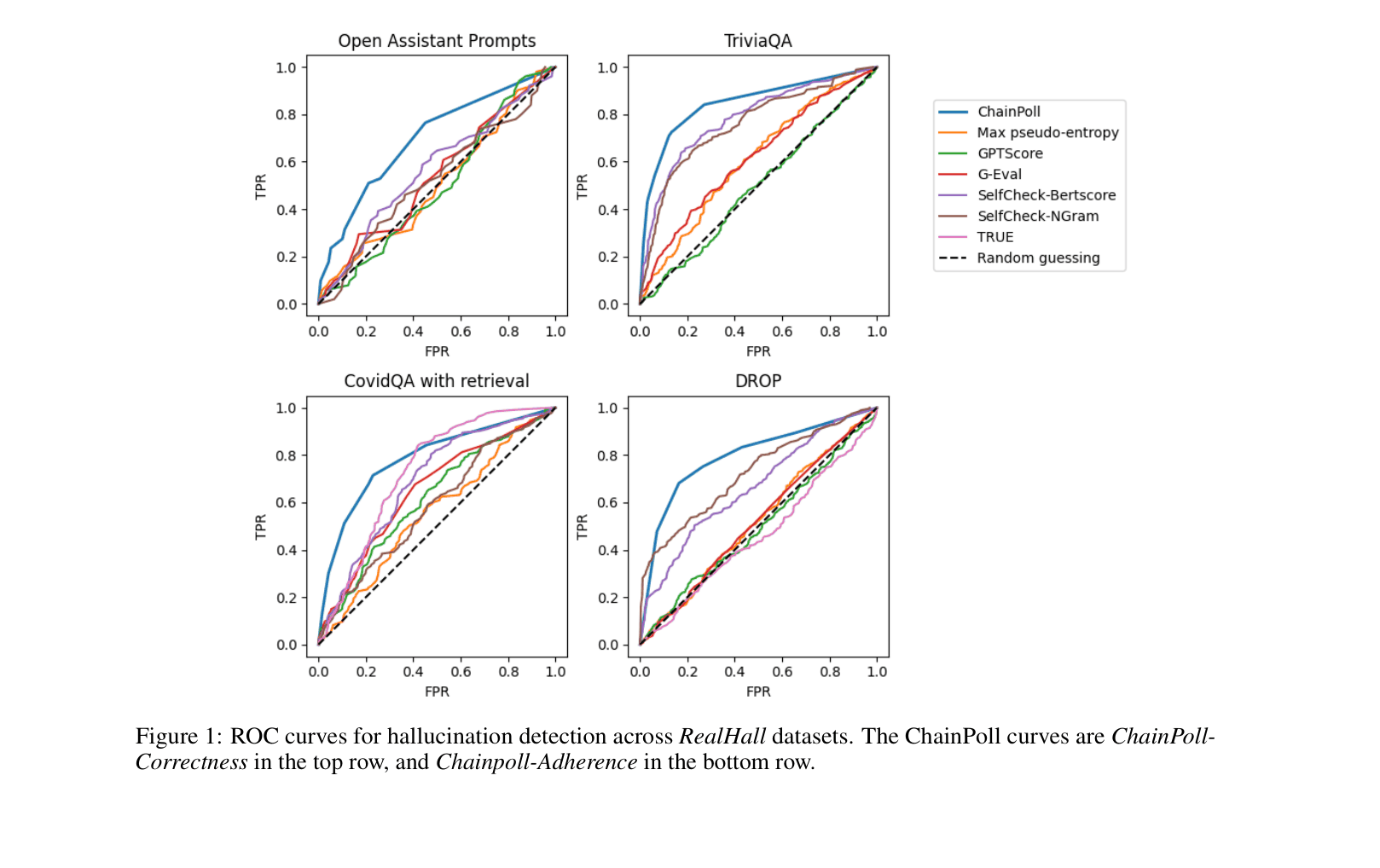
ROC curves for hallucination detection across RealHall datasets (COVID-QA, DROP, Open Assistant, TriviaQA)
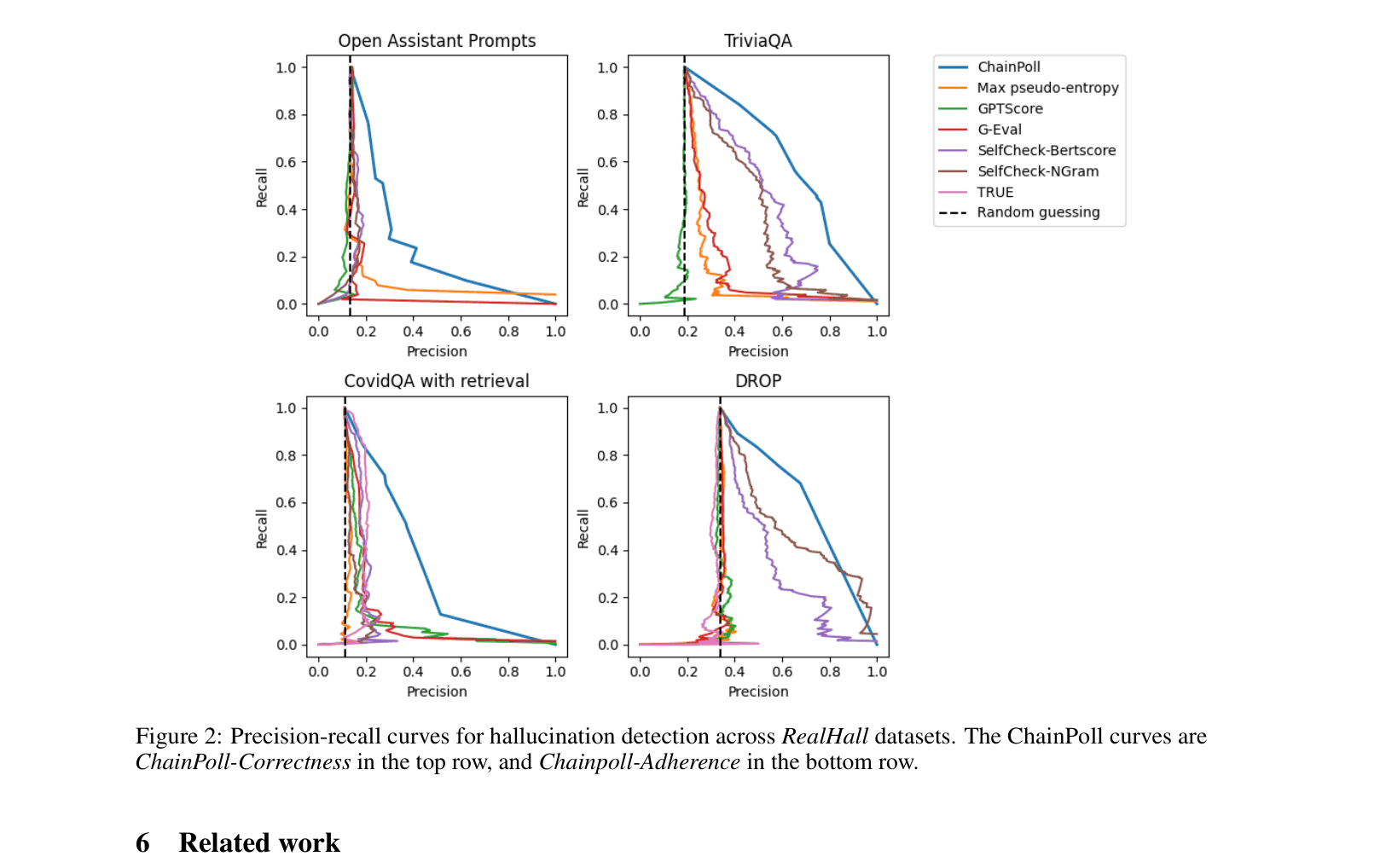
Precision-recall curves for hallucination detection across RealHall datasets
Main Takeaways
- ChainPoll consistently outperforms existing metrics (SelfCheckGPT, G-Eval, GPTScore, TRUE) on both open and closed domain tasks.
- Traditional metrics like GPTScore (perplexity) perform poorly (near random guessing) on modern, challenging benchmarks.
- Many existing benchmarks (SummEval, QAGS) are 'too easy' or irrelevant for SOTA LLMs; RealHall provides a necessary increase in difficulty.
- Boolean polling combined with Chain-of-Thought provides a sweet spot between cost and accuracy, beating expensive GPT-4 scalar evaluations.