📊 Experiments & Results
Evaluation Setup
Human evaluation of LLM summaries using a custom interface
Benchmarks:
- FaithBench (Summarization Hallucination Detection) [New]
Metrics:
- Hallucination Rate (Unwanted + Questionable / Total)
- Balanced Accuracy (for detectors)
- F1-Macro (for detectors)
- Krippendorff's alpha (Inter-Annotator Agreement)
- Statistical methodology: Krippendorff’s alpha for agreement. No significance tests reported for model rankings.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| LLM Hallucination Rankings on FaithBench Challenging Samples | ||||
| FaithBench | Hallucination Rate (lower is better) | 69.70 | 57.38 | -12.32 |
| FaithBench | Hallucination Rate (lower is better) | 57.38 | 63.93 | +6.55 |
| Detector Performance on FaithBench (Evaluating the evaluators) | ||||
| FaithBench | Balanced Accuracy | 50.00 | 58.00 | +8.00 |
| FaithBench | F1-Macro | 54.00 | 55.00 | +1.00 |
Experiment Figures
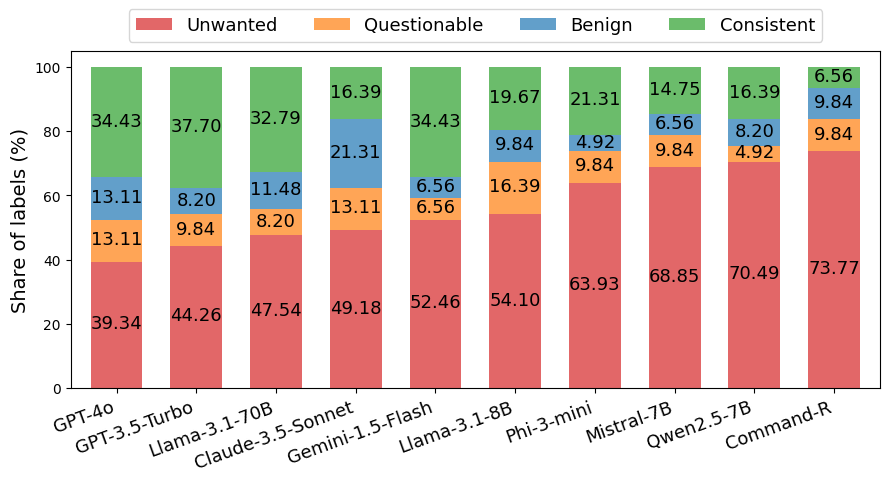
Distribution of sample-level labels (Consistent, Benign, Questionable, Unwanted) per LLM
Main Takeaways
- GPT-4o and GPT-3.5-Turbo produce the fewest hallucinations on challenging samples, outperforming newer open models like Llama-3.
- Claude-3.5-Sonnet has a high rate of 'benign' hallucinations, suggesting it adds useful but unfaithful information more often than others.
- Even state-of-the-art detectors (GPT-4o, HHEM-2.1) struggle significantly with FaithBench, achieving near-random (50-58%) balanced accuracy, proving the benchmark's difficulty.
- Subjectivity remains a major challenge: Inter-annotator agreement drops significantly when introducing 'benign' and 'questionable' categories compared to binary labeling.