📝 Paper Summary
Hallucination suppression
Confidence estimation
LoVeC uses reinforcement learning to train LLMs to append numerical confidence scores to every generated sentence, achieving efficient on-the-fly calibration for long-form text without expensive post-hoc sampling.
Core Problem
Existing confidence estimation methods for long-form generation are computationally expensive (requiring multiple samples or auxiliary models) or rely on prompt-based verbalization that is often poorly calibrated.
Why it matters:
- Hallucinations in high-stakes domains (medicine, law) require reliable confidence signals to trigger safe downstream strategies like selective answering or human review
- Post-hoc consistency checks (sampling multiple times) are too slow and costly for real-time applications
- Current verbalized confidence methods focus on short-form QA and do not generalize to open-ended long-form generation where certainty varies across sentences
Concrete Example:
When an LLM generates a long biography, it might be correct about the birth date but hallucinate the subject's education. A standard model outputs the whole text without differentiation; LoVeC appends '[10]' to the birth date sentence and '[2]' to the hallucinated education sentence during the single decoding pass.
Key Novelty
On-the-fly Sentence-Level Verbalized Confidence via RL
- Treats confidence generation as a sequential decision process where the model appends a token (e.g., '10') after every sentence representing its certainty
- Optimizes the model using Reinforcement Learning (RL) with a reward signal based on the alignment between the generated confidence score and the ground-truth factuality of the sentence
- Introduces 'Iterative Tagging' (grading fixed text) and 'Free-form Tagging' (generating text + grades) as distinct evaluation protocols
Architecture
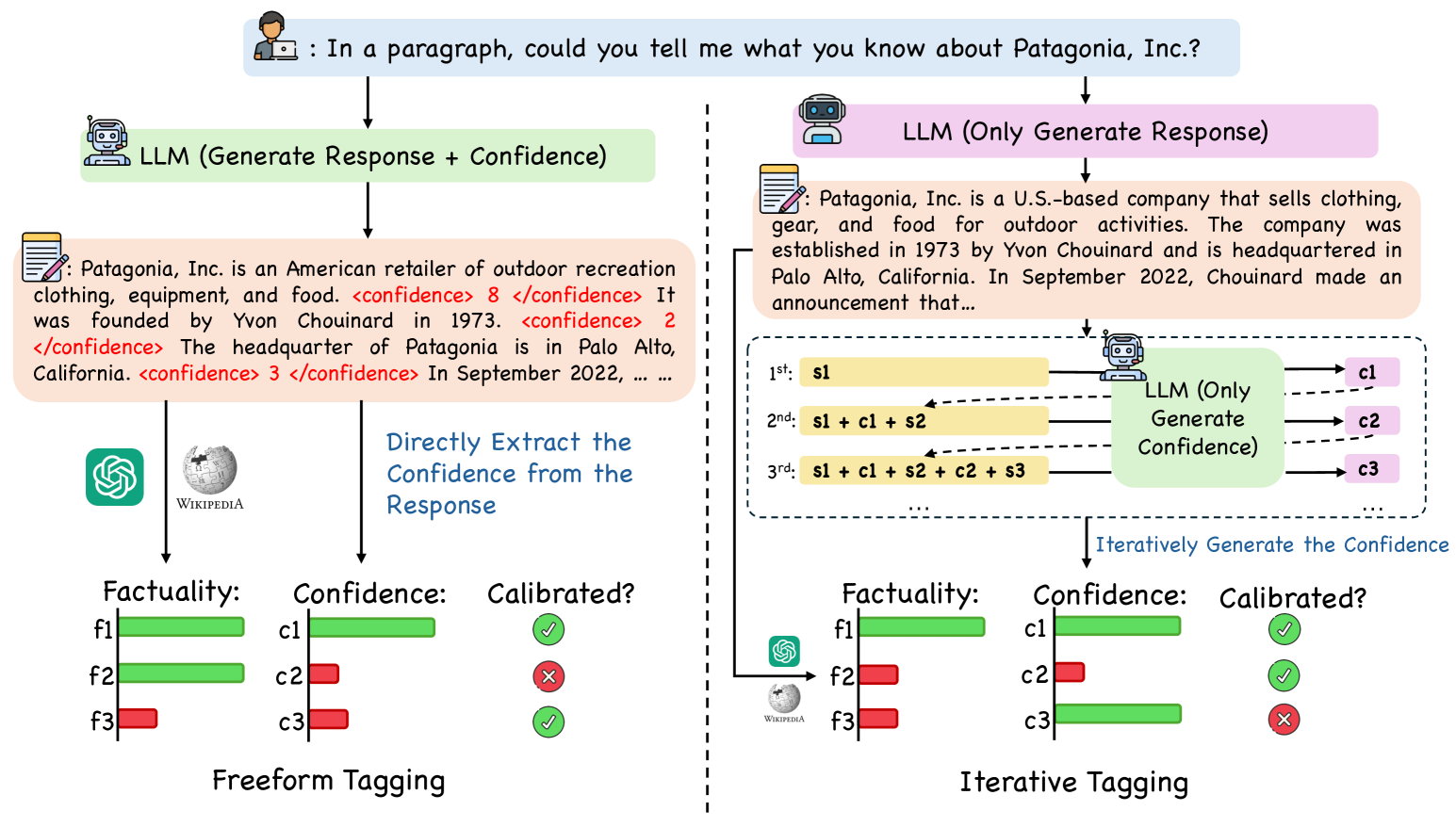
Overview of the LoVeC framework, illustrating the difference between Free-form Tagging (generating text + confidence) and Iterative Tagging (grading fixed text), and the RL training loop.
Evaluation Highlights
- Achieves up to 20x speedup compared to sampling-based state-of-the-art methods (like BS-Detector) while maintaining comparable calibration performance
- RL-trained models (specifically using GRPO or DPO) significantly outperform Supervised Fine-Tuning (SFT) and prompting baselines in calibration error metrics (ECE)
- Generalizes robustly from long-form training to short-form QA tasks, outperforming models trained specifically on short-form data
Breakthrough Assessment
8/10
Significant efficiency gain (20x) by eliminating sampling, combined with the novel application of RL for granular sentence-level calibration. Addresses a critical bottleneck in deploying reliable long-form generators.