📝 Paper Summary
Hallucination suppression
Confidence calibration
Rewarding Doubt fine-tunes LLMs to express calibrated numerical confidence scores alongside their answers by using a reinforcement learning reward function based on the logarithmic scoring rule.
Core Problem
LLMs often generate hallucinations with high confidence, and existing methods either decouple confidence estimation from generation (external probes) or lack inherent calibration awareness (zero-shot prompting).
Why it matters:
- In high-stakes fields like medical diagnosis or legal consultation, overconfident hallucinations can lead to dangerous misinformed decisions
- Reliable confidence expression is essential for human-AI collaboration, allowing systems to flag uncertain outputs for human review
- Current methods that rely on external probes or post-hoc analysis fail to give the model itself an intrinsic awareness of its own uncertainty
Concrete Example:
A medical LLM might incorrectly diagnose a rare condition with '100%' confidence, misleading a doctor. A calibrated model using this method would recognize its internal uncertainty and output a low confidence score (e.g., '20%'), signaling the need for verification.
Key Novelty
Rewarding Doubt
- Treats confidence estimation as a betting game where the model is rewarded for high confidence on correct answers and penalized for high confidence on incorrect ones
- Directly optimizes a strictly proper scoring rule (logarithmic score) via PPO (Proximal Policy Optimization), mathematically guaranteeing that the optimal policy is perfectly calibrated
- Integrates confidence calibration seamlessly into the generation process, unlike prior works that use external classifiers or separate preference models
Architecture
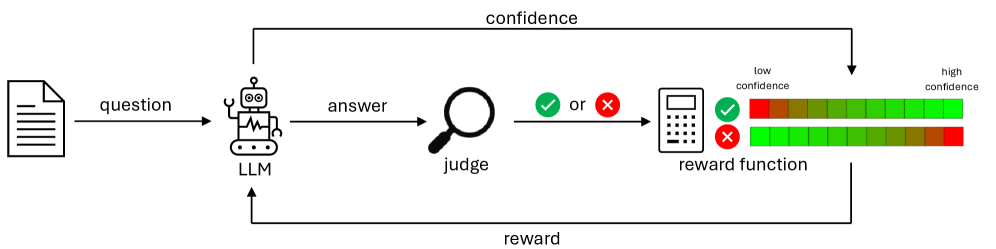
The Reinforcement Learning setup where the LLM acts as an agent in a QA environment.
Evaluation Highlights
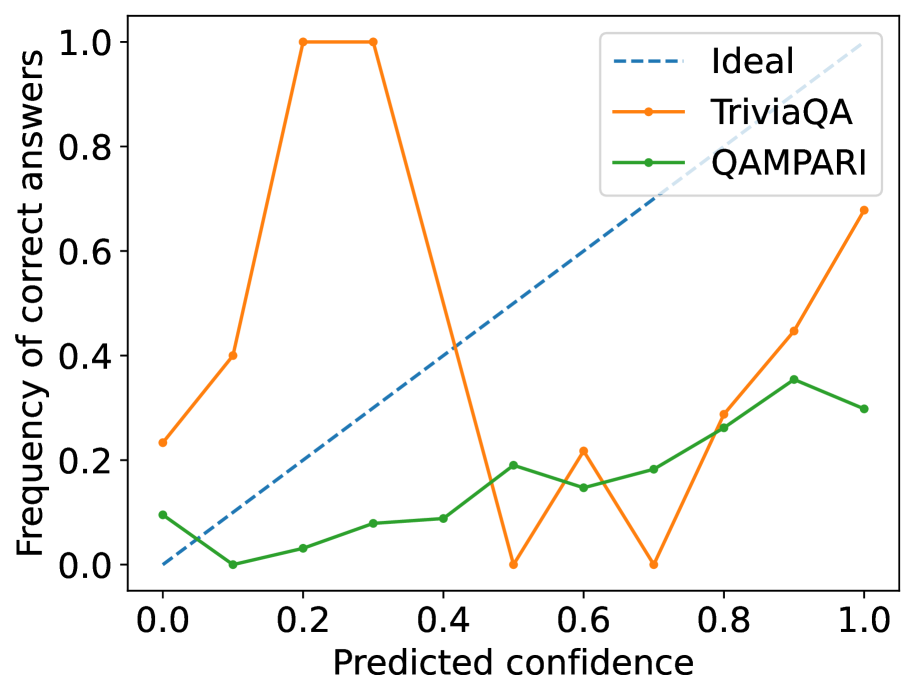
- Reduces Expected Calibration Error (ECE) to 0.05 on TriviaQA, outperforming the best baseline (Trained Probe) by roughly 50%
- Achieves 0.86 AUROC on TriviaQA, surpassing both zero-shot methods and DPO-based approaches like LACIE
- Demonstrates strong generalization to unseen medical (MedQA) and commonsense (CommonsenseQA) tasks without further fine-tuning, maintaining low ECE
Breakthrough Assessment
8/10
Provides a theoretically grounded RL approach to calibration that outperforms existing probe-based and prompting methods. The generalization to unseen domains suggests it instills genuine uncertainty awareness.