📝 Paper Summary
Hallucination suppression
Uncertainty Quantification (UQ)
The paper proposes a novel uncertainty quantification method, Claim-Conditioned Probability (CCP), which detects factual errors in LLM outputs by measuring uncertainty about the specific claim while ignoring irrelevant uncertainty about wording or claim order.
Core Problem
LLMs frequently hallucinate convincing but false claims, and existing fact-checking methods are either computationally expensive (requiring external knowledge/models) or imprecise because they conflate uncertainty about facts with uncertainty about wording/style.
Why it matters:
- Hallucinations are dangerous because occasional falsehoods are obscured by mostly correct text, making them hard for users to spot
- Standard uncertainty metrics (like entropy) are noisy because high uncertainty can result from harmless choices (e.g., synonyms) rather than factual ignorance
- Reliance on external databases for verification introduces latency, storage overhead, and issues with incomplete knowledge sources
Concrete Example:
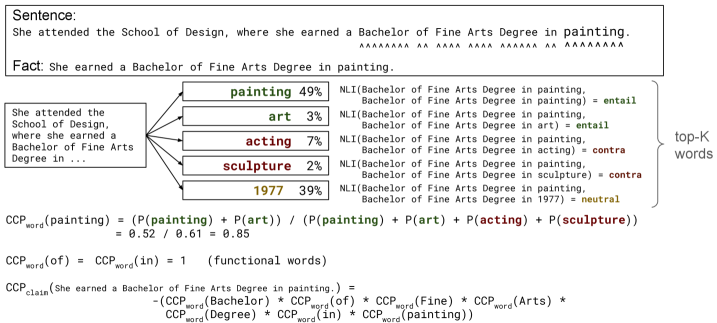
When generating a biography, a model might be uncertain whether to say 'studied art' or 'studied painting' (harmless surface form uncertainty), or it might be uncertain whether the person studied 'art' or 'physics' (factual claim uncertainty). Standard entropy treats both as high uncertainty, flagging correct text as unreliable, whereas the proposed method distinguishes them.
Key Novelty
Claim-Conditioned Probability (CCP)
- Quantifies uncertainty by checking if high-probability alternative tokens change the *meaning* of the sentence, rather than just the wording
- Uses a lightweight Natural Language Inference (NLI) model to compare the original generation against versions where specific words are swapped with their top alternatives
- Isolates 'Claim Uncertainty' (factual errors) by explicitly removing 'Surface Form Uncertainty' (synonyms) and 'Claim Order Uncertainty' (reordering of true facts)
Architecture
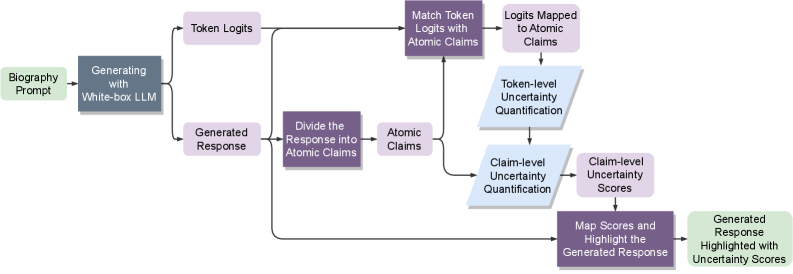
The complete fact-checking pipeline using token-level uncertainty quantification
Evaluation Highlights
- CCP achieves highest AUC-ROC (0.81 with Llama-2-7b-chat) for detecting hallucinations in biographies, outperforming P(True) and Neg Perplexity baselines
- Consistent performance across 4 languages (English, Chinese, Arabic, Russian) and 7 LLMs, often surpassing Maximum Probability by margins of ~0.05-0.10 AUC
- Human evaluation confirms CCP-based fact-checking is competitive with FactScore (which uses external Wikipedia retrieval), achieving similar precision without external access
Breakthrough Assessment
7/10
Strong methodological contribution in distinguishing types of uncertainty for white-box models. While it relies on an NLI model, it removes the need for external knowledge bases, offering a self-contained solution for hallucination detection.