📝 Paper Summary
Medical Multimodal Large Language Models (Med-MLLMs)
Reasoning-enhanced LLMs
Process Supervision
ChestX-Reasoner improves radiological diagnosis by mining structured reasoning chains from clinical reports and training a multimodal model using process supervision to align intermediate reasoning steps with clinical standards.
Core Problem
Medical AI models often prioritize final diagnostic outcomes while neglecting the structured, step-by-step reasoning processes inherent in clinical practice, leading to lower interpretability and performance.
Why it matters:
- Radiologists follow strict guidelines involving low-level anomaly identification before high-level diagnosis; AI should mirror this for clinical validity
- Existing methods rely on outcome-based reinforcement learning, which ignores the rich supervision available in the intermediate findings of radiology reports
- Accurate diagnosis requires analytical rigor, and lack of reasoning capabilities limits the reliability and trust in medical AI systems
Concrete Example:
In a chest X-ray analysis, a standard model might directly predict 'pneumonia' without explanation. A radiologist (and ChestX-Reasoner) would first identify 'opacities in the right lower lobe,' then rule out 'lung collapse' or 'heart enlargement,' before concluding 'pneumonia,' ensuring the diagnosis is grounded in specific visual evidence.
Key Novelty
ChestX-Reasoner: Process-Supervised Medical MLLM
- Automated mining of reasoning chains from unstructured radiology reports using GPT-4o to create structured 'Finding' → 'Impression' logical flows
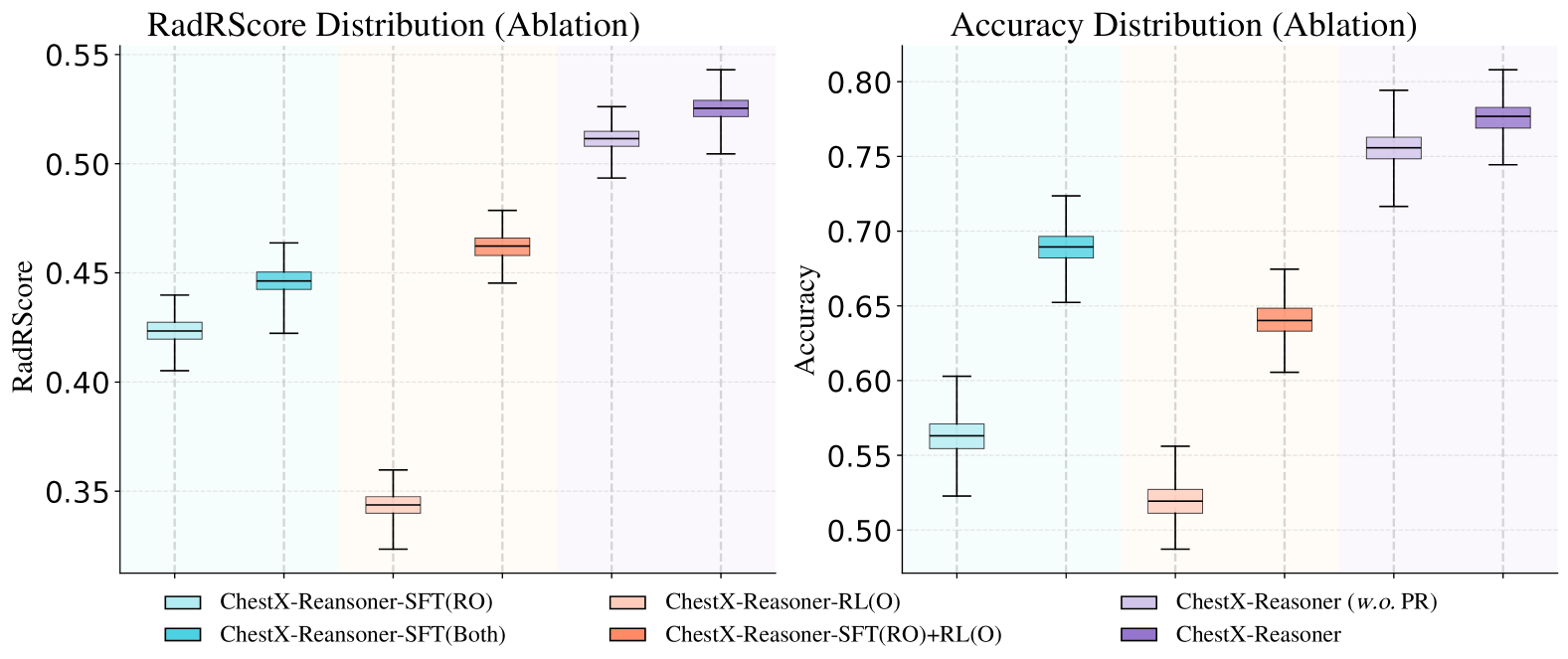
- Two-stage training: Supervised Fine-Tuning (SFT) on reasoning data followed by Reinforcement Learning (RL) with a novel process reward that validates intermediate reasoning steps against ground truth reports
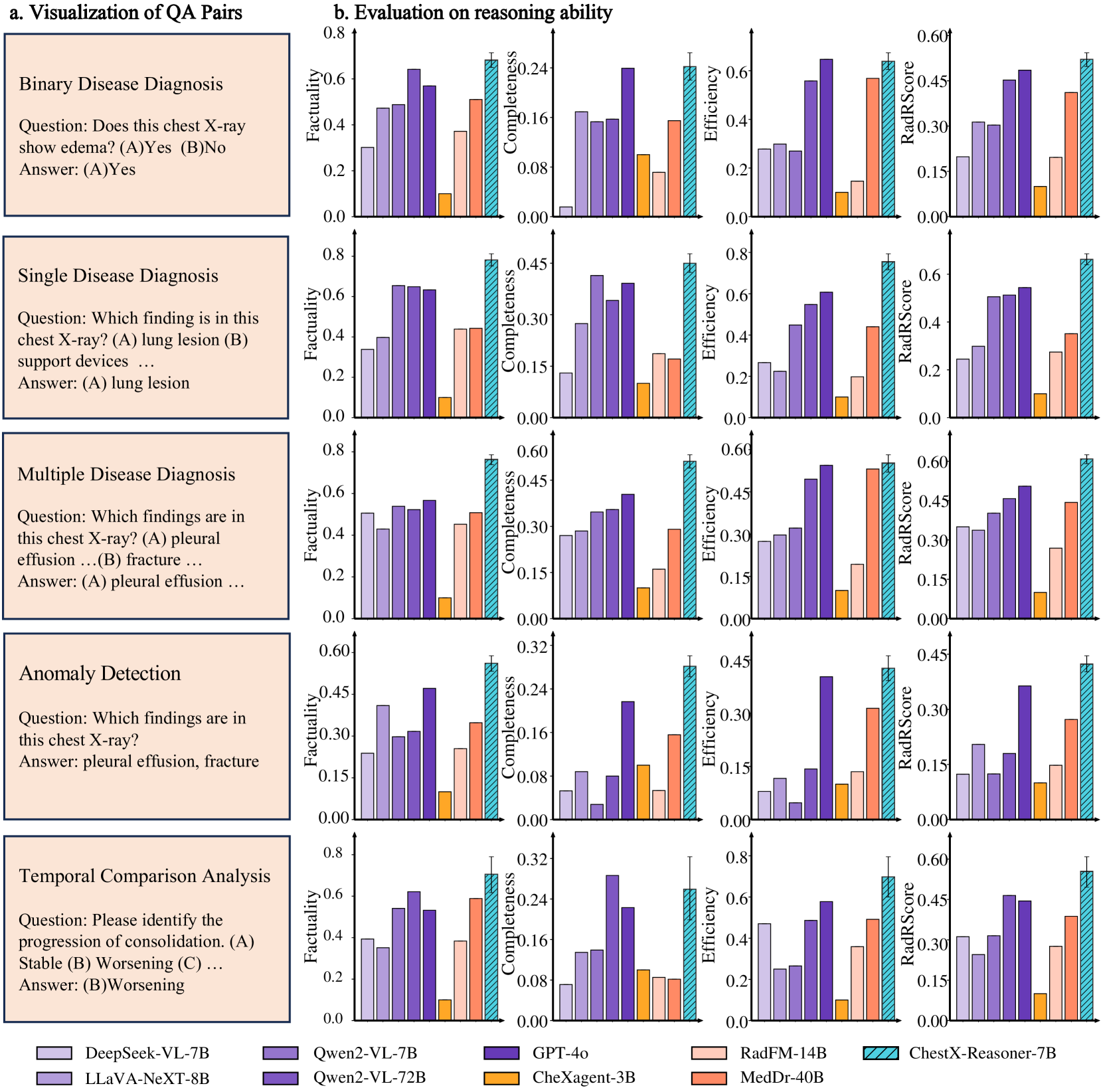
- Introduction of RadRBench-CXR (a benchmark with 59K reasoning-augmented samples) and RadRScore (a metric measuring factuality, completeness, and effectiveness of reasoning)
Architecture
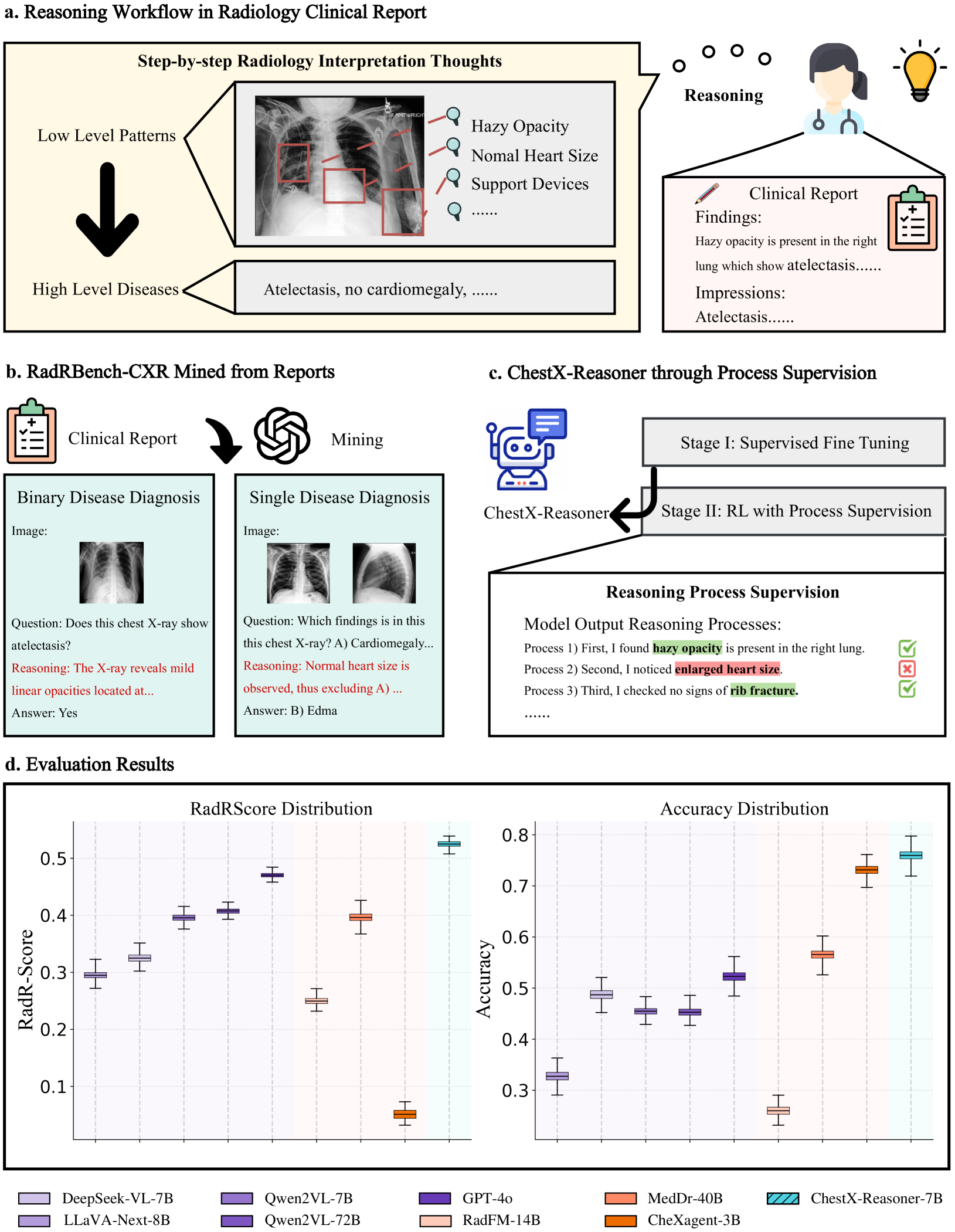
The two-stage training framework of ChestX-Reasoner.
Evaluation Highlights
- +18% improvement in reasoning ability (RadRScore) for ChestX-Reasoner compared to its base model Qwen2VL-7B
- +16% improvement in reasoning ability over the best medical baseline (MedDr-40B) and +8.5% over the best general baseline (GPT-4o)
- +27% improvement in outcome accuracy over the base model and +3.3% over the state-of-the-art medical MLLM (CheXagent-3B)
Breakthrough Assessment
8/10
Strong contribution by successfully applying process supervision (popular in math/code) to the medical domain via automated mining of clinical reports. Significant performance gains and a new comprehensive benchmark/metric.