📝 Paper Summary
Hallucination suppression
Factuality evaluation
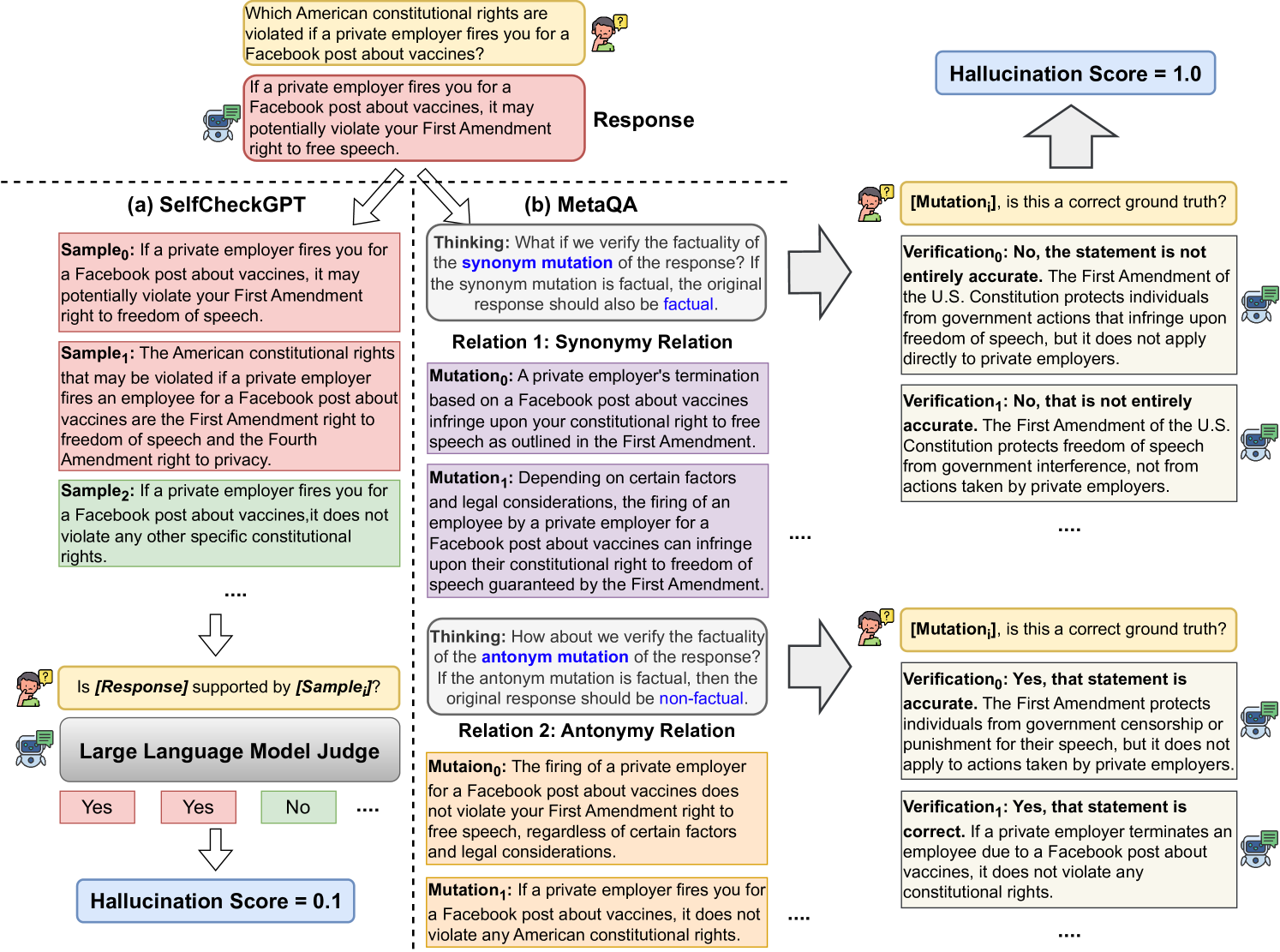
MetaQA detects LLM hallucinations without external databases by generating synonymous and antonymous mutations of a response and checking if the model's verification of these mutations is logically consistent.
Core Problem
Existing hallucination detection methods rely on unavailable external databases, privacy-invasive search engines, or inaccessible token probabilities (for closed models), while self-contained methods like SelfCheckGPT suffer because LLMs tend to repeat hallucinations when simply prompted multiple times.
Why it matters:
- Fact-conflicting hallucinations in high-stakes domains (e.g., legal, medical) can mislead users and erode trust in LLM applications
- Reliance on external resources limits detection to domains where comprehensive databases exist
- Output probability-based methods (e.g., token entropy) are impossible to use with black-box commercial models like GPT-4
Concrete Example:
When asked a legal question about 'Section 306 of the FD&C Act', ChatGPT hallucinates a response. SelfCheckGPT repeatedly asks the same question, receiving consistent incorrect answers (0.1 hallucination score). MetaQA mutates the response into antonyms (e.g., 'Does Section 306 NOT prohibit...'), forcing the model to reveal inconsistencies (1.0 score).
Key Novelty
Metamorphic Relation-based Hallucination Detection (MetaQA)
- Applies software testing principles (Metamorphic Relations) to natural language: if a statement is true, its synonym should be true and its antonym should be false according to the same model
- Uses the LLM itself to generate these mutations (synonyms/antonyms) and then verify them, acting as its own test oracle without needing external search engines or databases
- Calculates a hallucination score based on the logical consistency between the base response and its mutations
Architecture
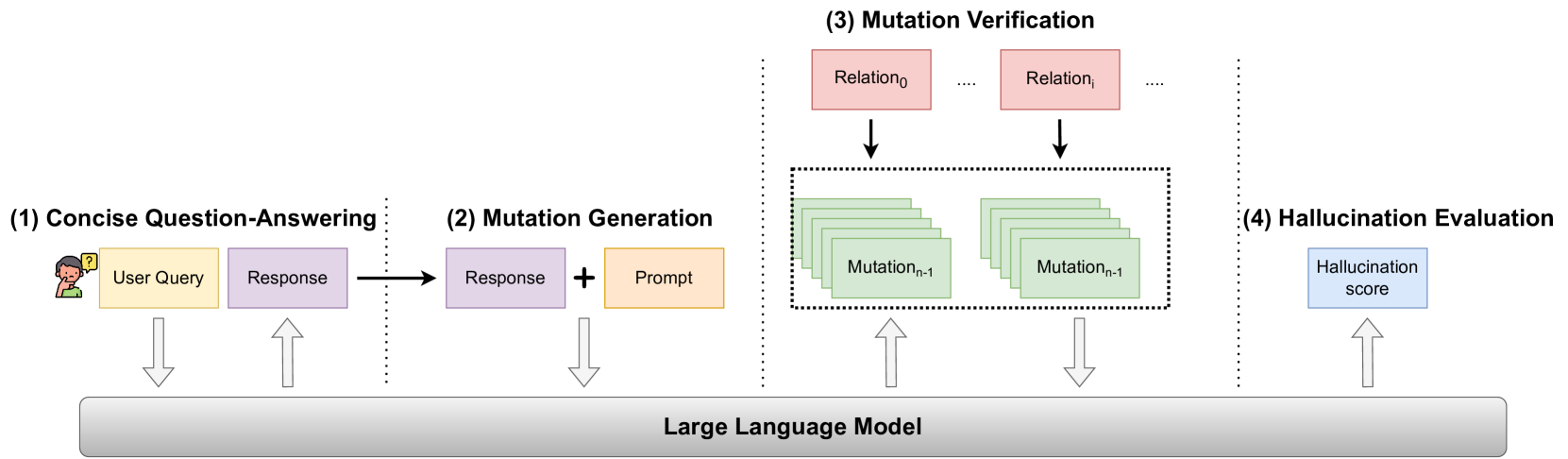
The 5-step workflow of the MetaQA framework.
Evaluation Highlights
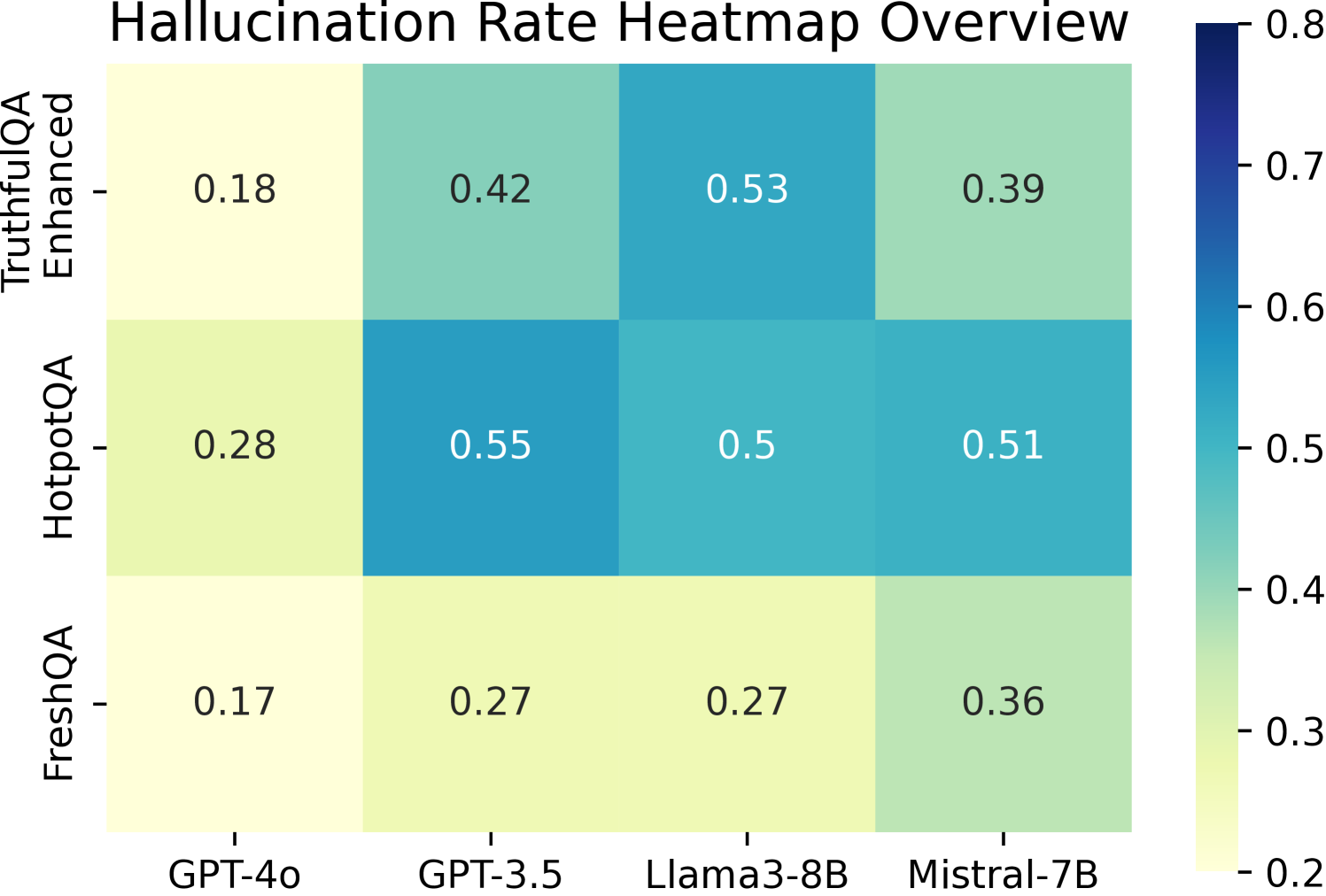
- MetaQA outperforms SelfCheckGPT on Mistral-7B with a +112.2% improvement in F1-score (0.435 vs 0.205)
- Superiority margin over SelfCheckGPT ranges from 0.154 to 0.368 in F1-score across four LLMs (GPT-4, GPT-3.5, Llama3, Mistral)
- Updates the TruthfulQA benchmark to create 'TruthfulQA-Enhanced' by correcting 238 questions, supporting more accurate evaluation
Breakthrough Assessment
7/10
Novel application of metamorphic testing to hallucination detection that outperforms the standard zero-resource baseline (SelfCheckGPT). While the method is clever and resource-efficient, it relies heavily on the model's ability to verify its own logic.