📝 Paper Summary
RAG Evaluation
Hallucination detection
Grounding attribution
GaRAGe is a RAG benchmark with human-annotated grounding for every retrieved passage, enabling precise evaluation of whether LLMs use only relevant information and deflect when grounding is insufficient.
Core Problem
Existing RAG benchmarks either evaluate final answers without checking if the grounding was actually used/relevant, or use synthetic/unannotated contexts that conflate retrieval quality with generation quality.
Why it matters:
- Current metrics often reward 'correct' answers that ignore provided context (parametric memory), risking hallucination in real-world private data scenarios
- LLMs frequently summarize all retrieved documents regardless of relevance, rather than filtering out noise
- Real-world RAG systems must 'deflect' (refuse to answer) when retrieved information is insufficient, a capability rarely tested in current benchmarks
Concrete Example:
A user asks about a specific policy update. The retriever returns an outdated policy document (irrelevant) and a generic web snippet. A standard LLM might hallucinate an answer based on training data or summarize the outdated policy. GaRAGe penalizes this by checking if the model strictly used passages annotated as 'relevant' or correctly deflected.
Key Novelty
GaRAGe (Grounding Annotations for RAG evaluation)
- Provides snippet-level human annotations for 35k+ passages, labeling each as 'relevant', 'related', 'outdated', or 'unknown' relative to the question
- Introduces Relevance-Aware Factuality (RAF), a metric that penalizes models for using information from retrieved passages that are actually irrelevant or outdated
- Includes a specific evaluation subset for 'deflection', where the grounding is intentionally insufficient, testing the model's ability to say 'I don't know' instead of hallucinating
Architecture
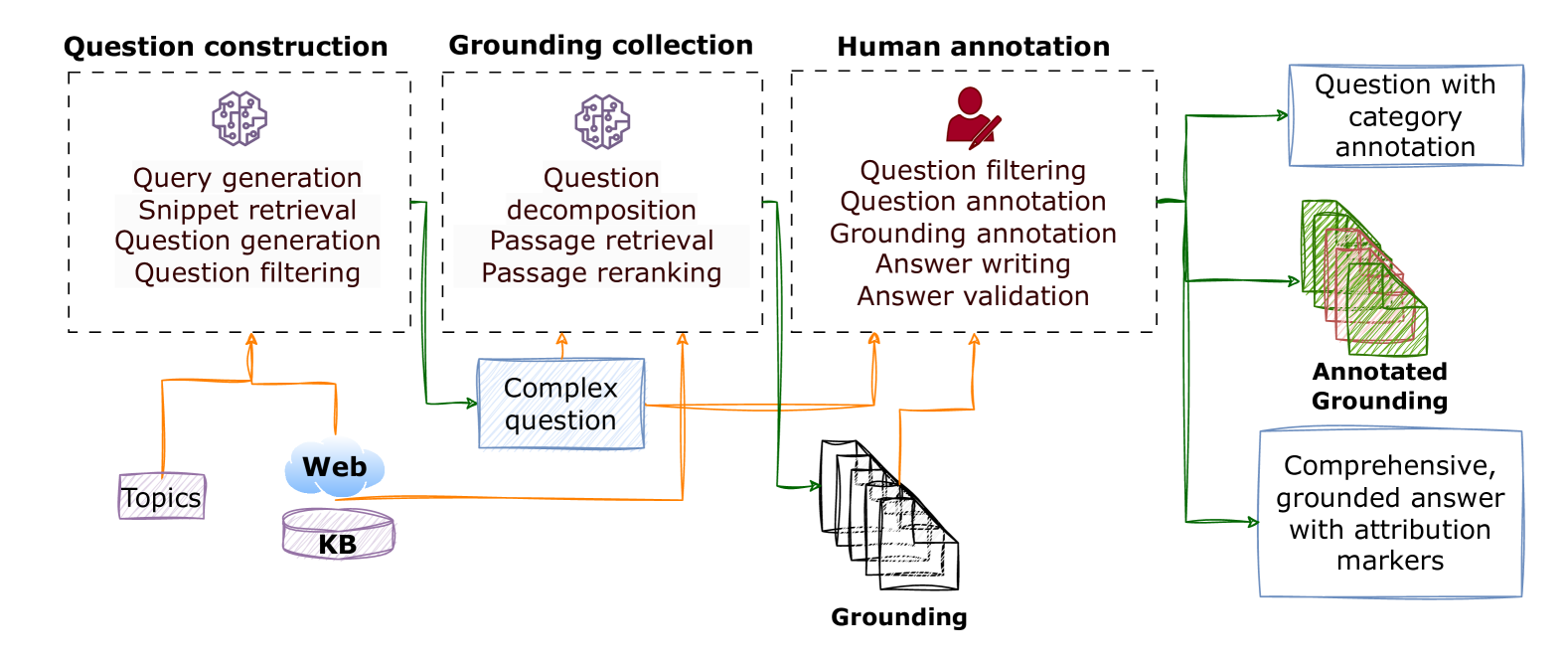
The dataset construction pipeline for GaRAGe.
Evaluation Highlights
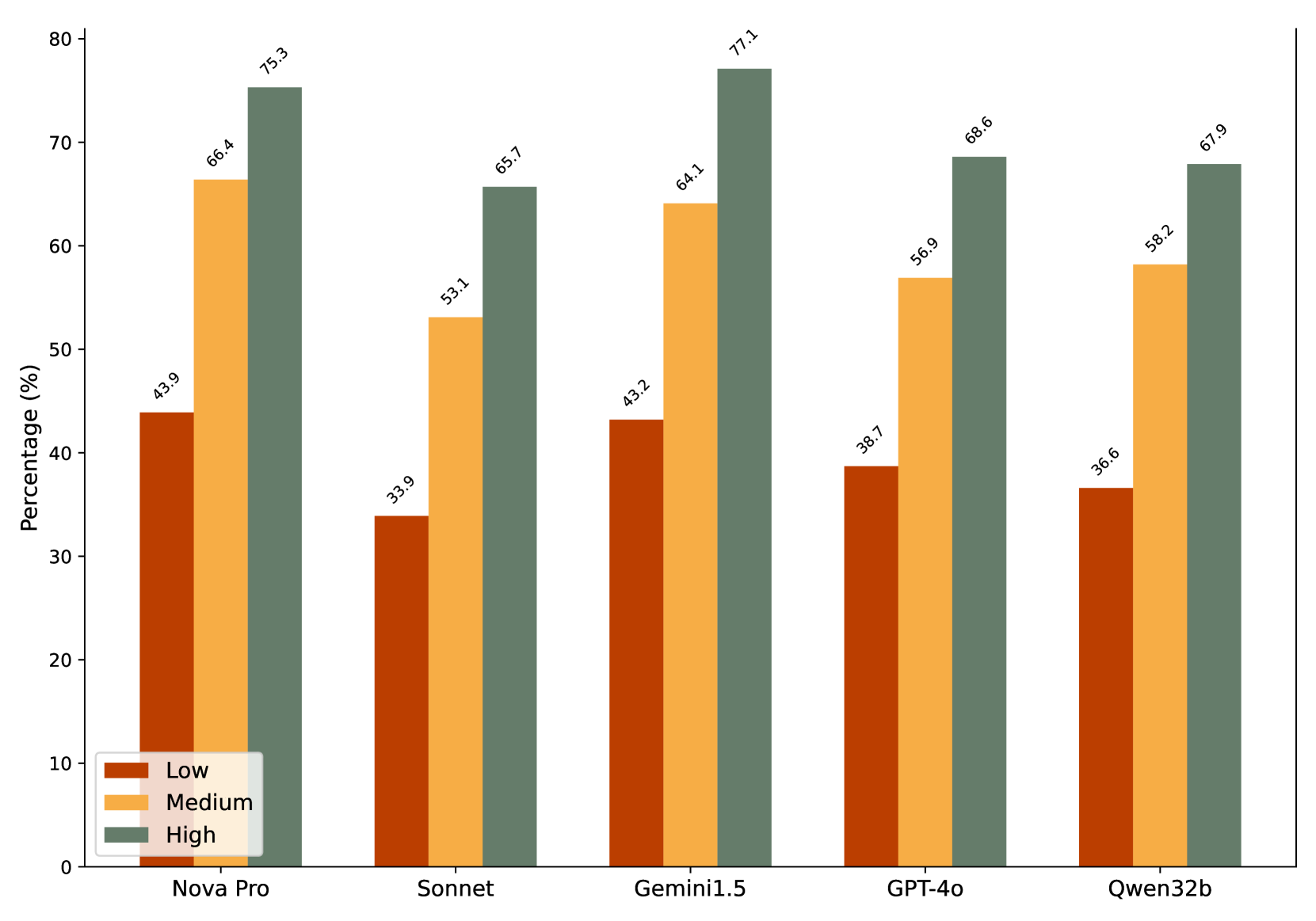
- State-of-the-art models (including GPT-4o) reach at most 60% on Relevance-Aware Factuality (RAF), showing they struggle to filter irrelevant context
- In deflection scenarios (insufficient grounding), the best model (GPT-4o) achieves only a 31.1% true positive rate, frequently hallucinating answers instead of refusing
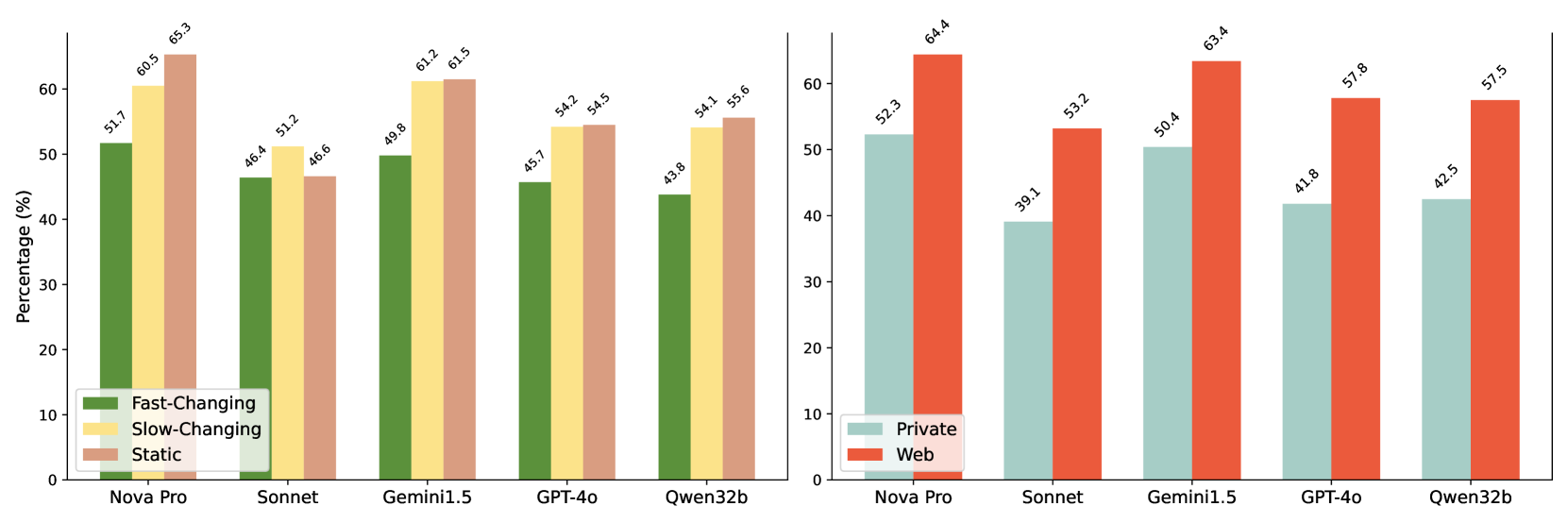
- Performance drops significantly (~10%) on time-sensitive 'Fast-Changing' questions, indicating LLMs struggle to reason about the temporal validity of grounding
Breakthrough Assessment
8/10
Significant contribution to RAG evaluation by addressing the 'black box' nature of context usage. The granular human annotation of grounding relevance allows for much stricter and more realistic assessment of hallucination and noise robustness than existing datasets.