📝 Paper Summary
Medical LLM Benchmarking
Clinical Reasoning Evaluation
Rare Disease Diagnosis
MedR-Bench introduces a dataset of 1,453 structured patient cases and an automated Reasoning Evaluator to assess LLMs' clinical reasoning processes alongside their final diagnostic outputs.
Core Problem
Existing medical LLM benchmarks primarily evaluate final outputs (e.g., diagnosis accuracy) while neglecting the quality, transparency, and coherence of the reasoning process itself.
Why it matters:
- Clinical practice requires constructing logical reasoning chains from incomplete information, not just guessing the final label
- Evaluating only final answers fails to capture whether the model reached the right conclusion for the right reasons (safety and reliability)
- Current benchmarks lack sufficient coverage of the full patient care journey, specifically missing examination recommendation and complex treatment planning
Concrete Example:
A model might correctly diagnose 'appendicitis' based on keywords but fail to recommend the necessary confirmative CT scan or explain *why* it ruled out diverticulitis, making the correct diagnosis brittle and untrustworthy in practice.
Key Novelty
Reasoning-Centric Clinical Evaluation Framework
- Deconstructs clinical cases into three stages (examination recommendation, diagnosis, treatment) to simulate the full patient care trajectory rather than just QA
- Introduces the 'Reasoning Evaluator', an automated system that cross-references free-text reasoning with web-scale medical resources to score efficiency, factuality, and completeness
- Includes a dedicated subset of rare diseases (656 cases) to test robustness on long-tail medical conditions
Architecture
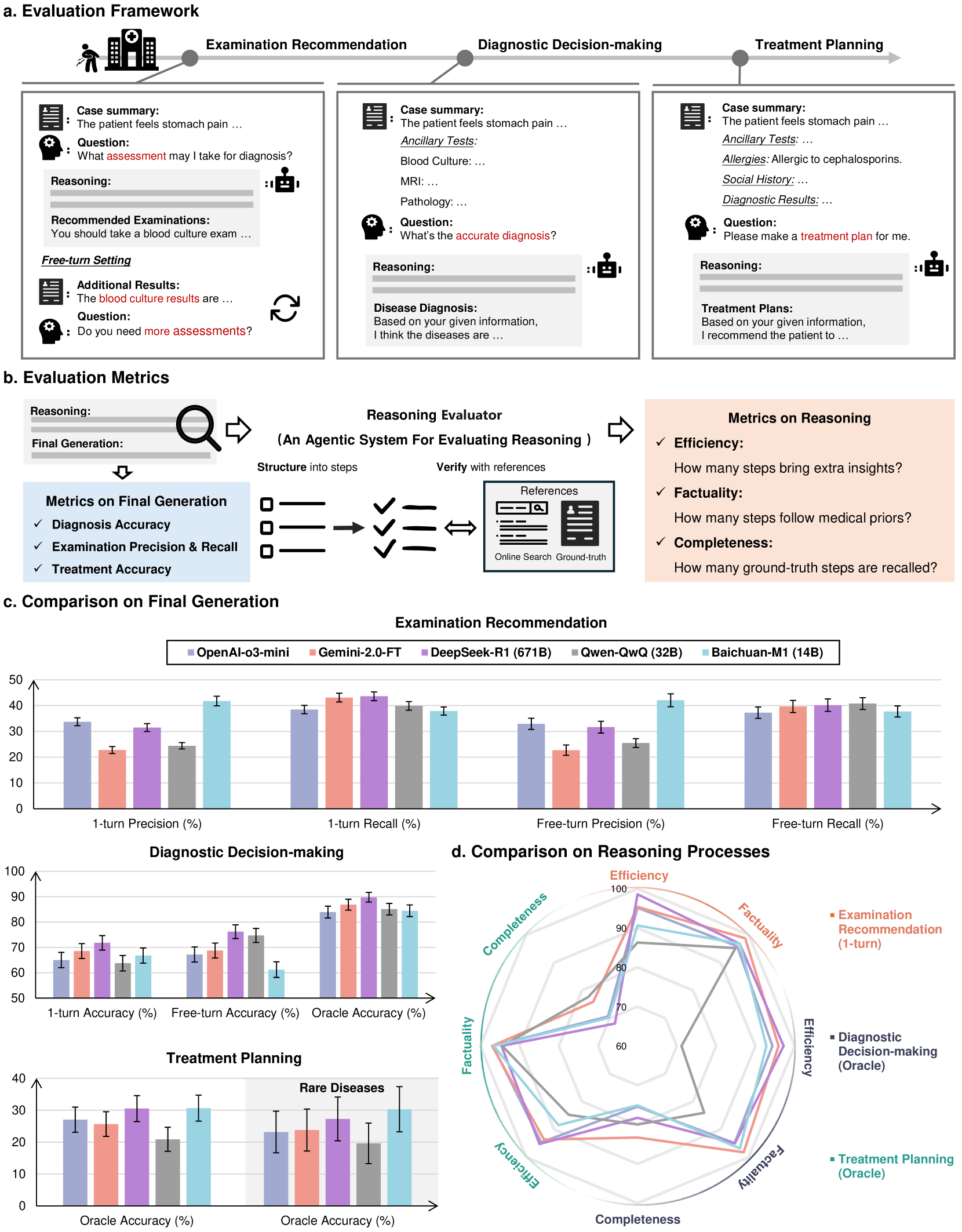
The MedR-Bench evaluation framework illustrating the three stages of the patient care journey simulation.
Evaluation Highlights
- DeepSeek-R1 achieves 89.76% diagnostic accuracy in the oracle setting (where all info is provided), outperforming OpenAI-o3-mini (84.53%)
- In the Examination Recommendation task (1-turn), precision is low across the board; Baichuan-M1 leads with only 41.78%, while Gemini-2.0-FT drops to 22.77%
- Factuality of reasoning steps is generally high (>90% for most models), but Completeness varies widely, with Qwen-QwQ achieving 79.97% completeness in diagnosis due to verbose outputs
Breakthrough Assessment
8/10
Significant step forward by moving beyond accuracy metrics to process-based evaluation in medicine. The automated Reasoning Evaluator addresses a major bottleneck in evaluating free-text clinical reasoning.