📝 Paper Summary
Vision-Language Model Alignment
Hallucination Mitigation
Preference Optimization
POVID aligns vision-language models by generating synthetic dispreferred data—hallucinating text via GPT-4V and distorting images to trigger inherent errors—then fine-tuning via Direct Preference Optimization.
Core Problem
Vision Large Language Models (VLLMs) hallucinate because text generation is not perfectly aligned with visual inputs, often prioritizing language priors over image content.
Why it matters:
- Current preference tuning methods (like RLHF) rely on costly human data or model-generated pairs where both answers might be wrong, failing to anchor the correct answer to the image
- Hallucinations in VLLMs pose significant risks in high-stakes deployment scenarios like medical imaging or autonomous driving
- Existing methods struggle to create effective 'negative' samples that specifically target the disconnect between visual perception and text generation
Concrete Example:
Given an image of a table with a knife and oranges, a standard VLLM might hallucinate a 'fork' because it statistically co-occurs with 'knife' in text data, ignoring the actual image. POVID deliberately distorts the image to force this error, then trains the model to reject it.
Key Novelty
Preference Optimization with AI-Generated Dispreferences (POVID)
- Generates negative training data (dispreferences) automatically without humans, using two strategies: asking GPT-4V to insert plausible hallucinations into correct text, and adding noise to images to trigger the model's own internal errors
- Uses Direct Preference Optimization (DPO) to contrast these synthetic hallucinations against ground-truth descriptions, forcing the model to trust visual cues over language priors
Architecture
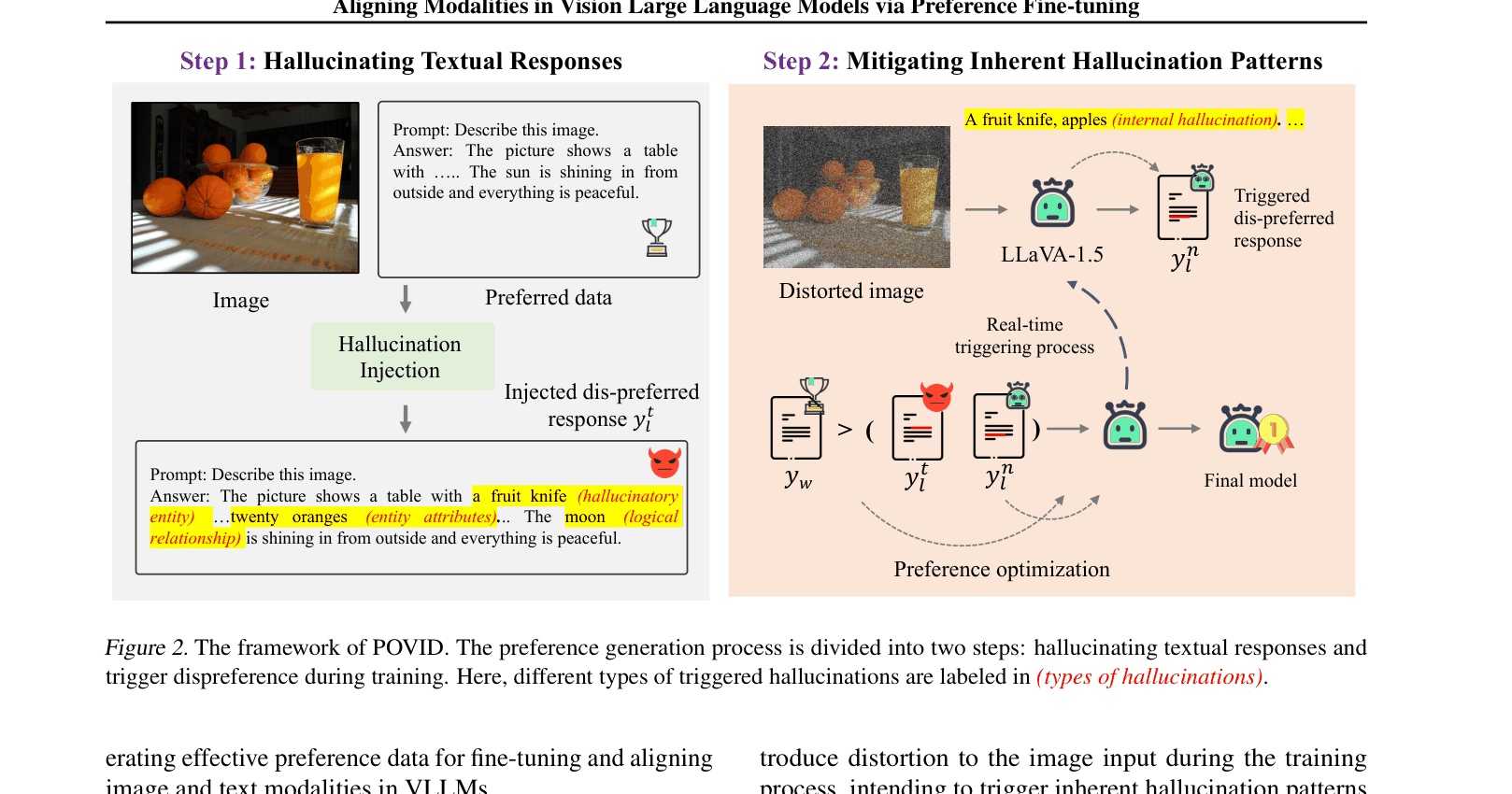
The POVID framework's data generation and training pipeline.
Evaluation Highlights
- Reduces object hallucination metric (CHAIRS) to 31.8 on the CHAIR benchmark, significantly outperforming the base LLaVA-1.5 model (66.8)
- Achieves 68.7 on LLaVA-Bench, surpassing RLHF-V (65.4) and LLaVA-1.5 (63.4) without using human preference data
- Outperforms larger models like InstructBLIP and Qwen-VL-Chat on 5 out of 8 benchmarks despite using a smaller 7B backbone
Breakthrough Assessment
8/10
Significantly outperforms human-feedback methods using only AI-generated data. The dual strategy of text-injection and image-noise triggering is a clever, scalable solution to the alignment problem.