📝 Paper Summary
Hallucination suppression
Fact-checking / Verification
Knowledge internalization (via synthetic data)
MiniCheck is a small (770M parameter) fact-checking model that matches GPT-4 performance at 400x lower cost by training on novel synthetic data requiring multi-sentence reasoning.
Core Problem
Verifying LLM outputs against evidence is computationally expensive using large models like GPT-4, while smaller specialized models struggle with complex, multi-fact reasoning.
Why it matters:
- Current methods like self-verification with LLMs are too costly (e.g., checking 40 facts against 5 documents results in 200+ checks per response)
- Specialized smaller models often fail to recognize when a claim aggregates information across multiple sentences or contains multiple atomic facts
- Existing datasets (MNLI, ANLI) do not reflect the complexity of modern LLM hallucination patterns
Concrete Example:
An LLM claims 'Two people argue about weather and labor issues.' The document contains two separate sentences: one person mentions weather, another mentions labor. A standard entailment model might incorrectly flag this as unsupported because no single sentence contains both topics, whereas MiniCheck correctly aggregates evidence across sentences.
Key Novelty
Synthetic Data for Complex Fact-Checking (C2D & D2C)
- Generates synthetic training data where verifying a claim requires combining information from multiple sentences (Claim-to-Doc and Doc-to-Claim methods)
- Constructs 'hard negatives' by removing specific sentences from the evidence that support only part of a complex claim, forcing the model to verify *all* atomic facts
- Unifies 10 existing datasets into a new benchmark (LLM-AggreFact) to evaluate fact-checking across diverse grounding settings
Architecture
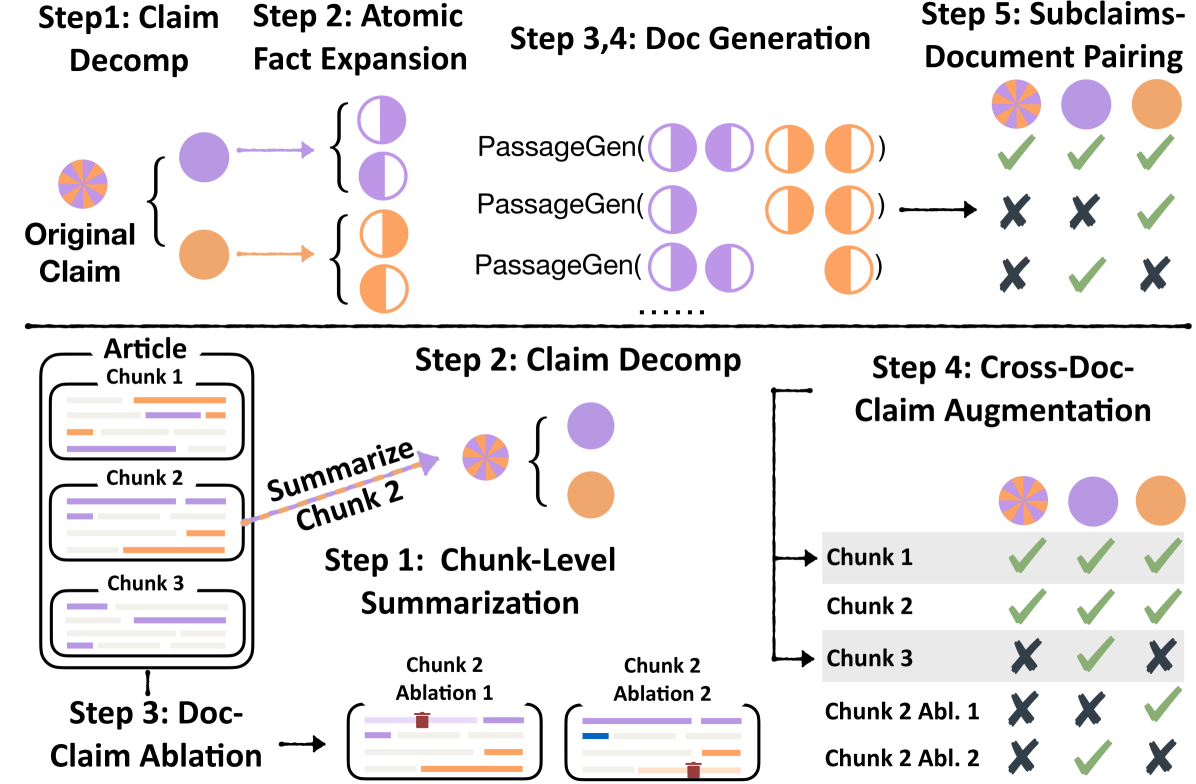
The synthetic data generation process (Claim-to-Doc and Doc-to-Claim).
Evaluation Highlights
- MiniCheck-FT5 (770M params) reaches GPT-4 performance levels on the LLM-AggreFact benchmark while being 400x cheaper
- Outperforms AlignScore-Large (355M params), the previous state-of-the-art specialized model, by ~4-10% accuracy
- Demonstrates that decomposing sentences into atomic facts is unnecessary for high performance when using MiniCheck
Breakthrough Assessment
9/10
Achieving GPT-4 level performance with a 770M parameter model on a critical task like hallucination detection is a significant efficiency breakthrough. The synthetic data methodology is highly generalizable.