📝 Paper Summary
Mathematical Reasoning
Long-chain Reasoning
Preference Alignment
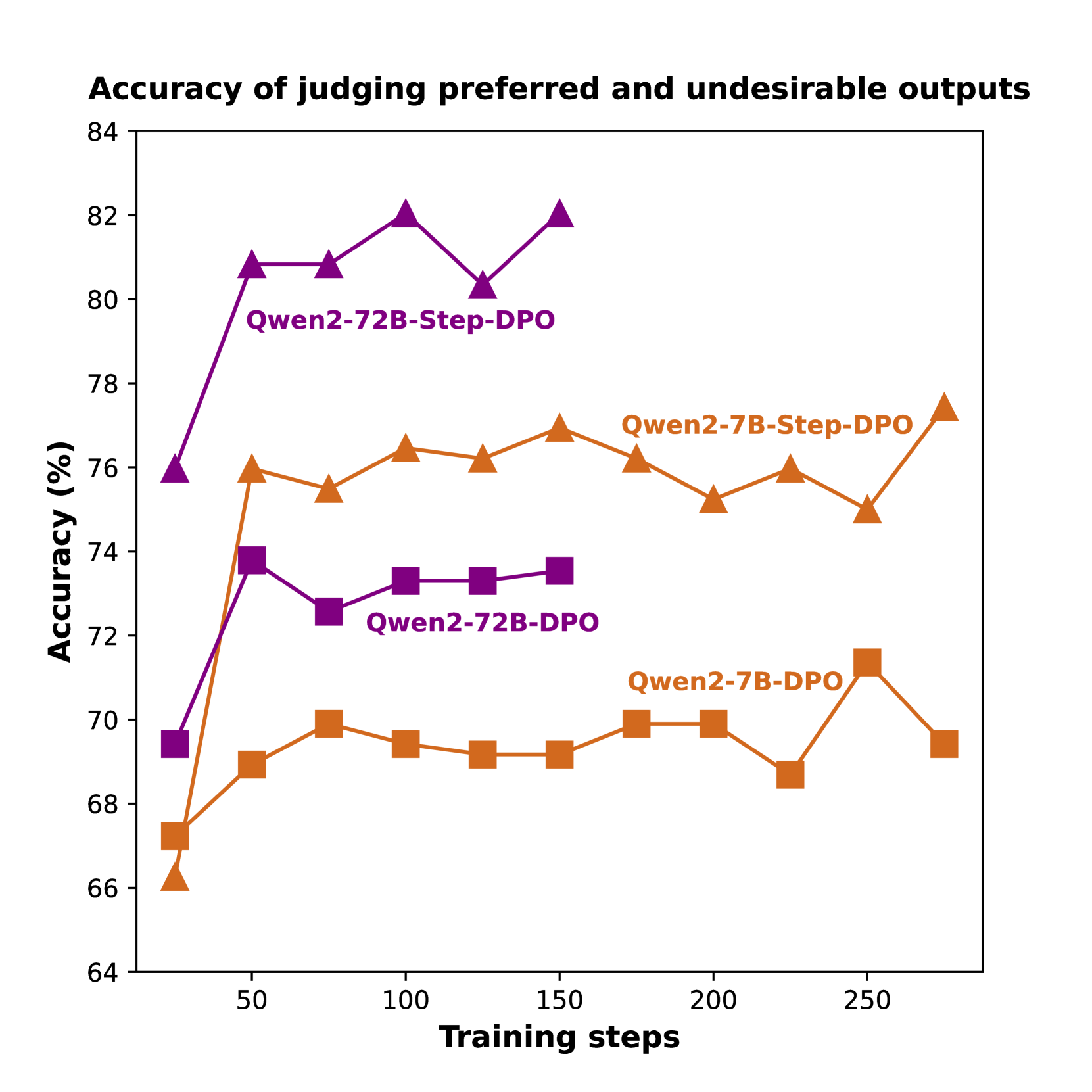
Step-DPO improves mathematical reasoning by performing Direct Preference Optimization on individual reasoning steps rather than holistic answers, using a data pipeline that pairs self-generated correct steps against specific errors.
Core Problem
Standard Direct Preference Optimization (DPO) fails in long-chain mathematical reasoning because it rejects entire answers based on a single error, discarding valid intermediate steps and providing insufficient supervision.
Why it matters:
- Models fine-tuned with vanilla DPO struggle to distinguish between preferred and undesirable outputs in math tasks, often failing to identify the specific error location.
- Supervised Fine-Tuning (SFT) alone leads to hallucinations as the probability of undesirable outputs increases alongside preferred ones.
- Existing solutions like outcome-based DPO plateau quickly, as the reward margin between correct and incorrect answers remains small.
Concrete Example:
In a multi-step math problem, if a model performs 5 correct steps and makes a calculation error in step 6, vanilla DPO rejects the entire sequence. Step-DPO instead identifies step 6 as the error, keeps steps 1-5 as context, and optimizes the preference between a corrected step 6 and the erroneous step 6.
Key Novelty
Step-wise Direct Preference Optimization (Step-DPO)
- Decomposes preference optimization into individual reasoning steps, treating the first erroneous step as the negative sample and a self-generated correction as the positive sample.
- Introduces a data construction pipeline (Error Collection → Step Localization → Rectification) that generates 10K high-quality step-wise preference pairs.
- Uses in-distribution (self-generated) corrections for the positive samples, which are shown to be more effective for alignment than out-of-distribution human or GPT-4 corrections.
Architecture
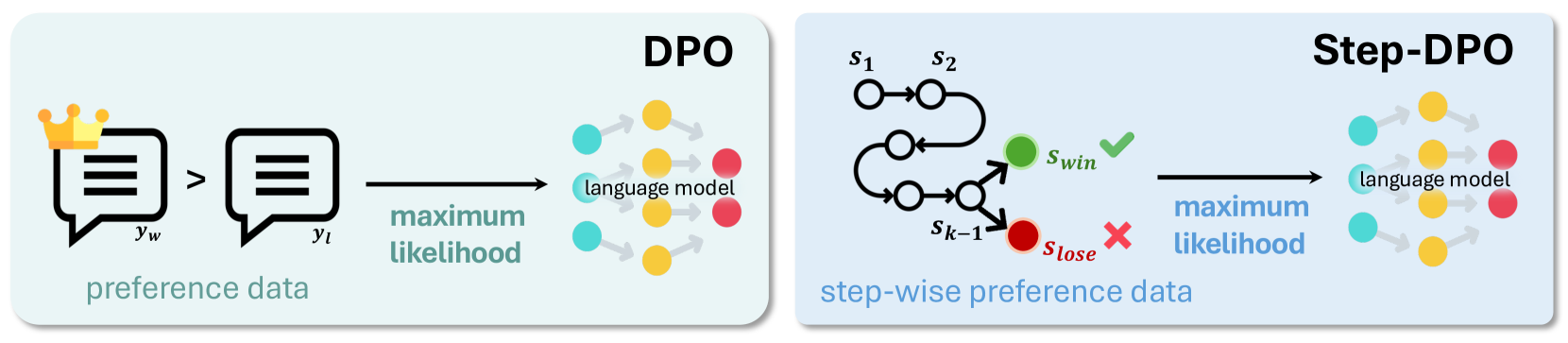
Comparison between Vanilla DPO and Step-DPO optimization objectives.
Evaluation Highlights
- Achieves 70.8% accuracy on MATH and 94.0% on GSM8K with Qwen2-72B-Instruct, surpassing GPT-4-1106 and Claude-3-Opus.
- Yields nearly 3% accuracy gain on MATH for 70B+ parameter models using fewer than 500 training steps and only 10K data pairs.
- Outperforms vanilla DPO significantly; e.g., on Qwen1.5-7B-Instruct, Step-DPO achieves 53.0% on MATH vs. 49.3% for DPO.
Breakthrough Assessment
8/10
Significant improvement over standard DPO for reasoning tasks with a highly data-efficient method (only 10k examples). effectively addresses the credit assignment problem in long chains.