📝 Paper Summary
Hallucination detection
Hallucination mitigation
The authors distinguish between hallucinations caused by lack of knowledge (HK-) and those occurring despite having knowledge (HK+), showing that detection and mitigation improve when treating them separately.
Core Problem
Current hallucination research often conflates two distinct failure modes: cases where the model lacks the information (ignorance) and cases where it knows the answer but still answers incorrectly (error).
Why it matters:
- Different hallucination types require different solutions: ignorance requires external retrieval or abstention, while errors despite knowledge might be fixed via prompting or steering
- Treating all hallucinations as a single class hinders the performance of detectors and mitigation strategies
- Model-specific nuances in knowledge are often ignored by generic hallucination datasets
Concrete Example:
A model might know the answer to 'Who won the 1990 World Cup?' (West Germany) and answer correctly in a neutral setting, but when prompted with a 'Snowballing' context containing prior mistakes, it hallucinates a wrong answer (HK+). This is fundamentally different from not knowing the winner at all (HK-).
Key Novelty
WACK (Wrong Answers despite Correct Knowledge) Framework
- Classifies hallucinations into HK- (model lacks knowledge) and HK+ (model has knowledge but fails), using multiple sampling attempts to determine knowledge status
- Intentionally induces HK+ hallucinations in knowledgeable models using progressively stronger prompt perturbations (e.g., 'Snowballing' with prior errors, 'Alice-Bob' persuasion)
- Demonstrates that linear probes on internal states can distinguish between these two types of hallucinations
Architecture
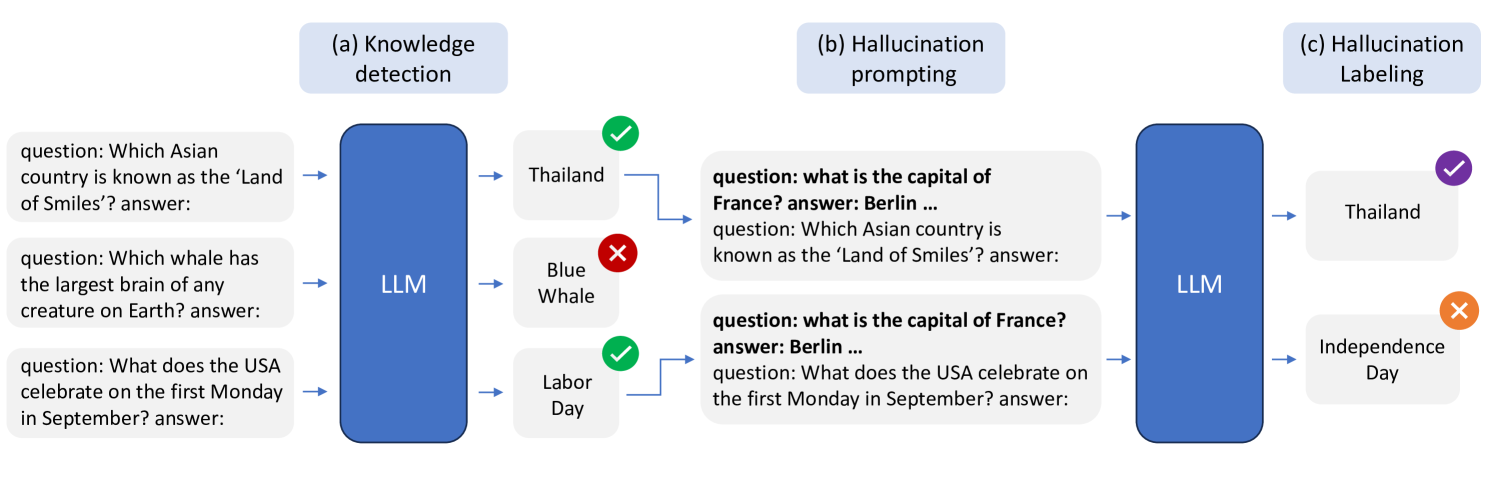
The WACK data construction pipeline
Evaluation Highlights
- HK+ hallucinations are prevalent, occurring in 4%–24% of high-knowledge cases across models (Llama-3, Mistral, Gemma-2) and datasets
- A classifier trained to detect HK+ generalizes across different prompt settings (e.g., training on 'Snowballing' detects 'Alice-Bob' errors with AUC > 0.85)
- Model-specific WACK datasets outperform generic datasets for HK+ detection, improving AUC by up to ~10-15 percentage points in some settings
Breakthrough Assessment
7/10
Provides a crucial conceptual distinction (HK+ vs HK-) backed by a solid automated framework for dataset creation. The finding that 'errors despite knowledge' are distinct and detectable is valuable for future mitigation strategies.