📝 Paper Summary
Generative Recommendation
LLM-based Recommendation
GRLM replaces numerical IDs with 'Term IDs'—structured sets of semantic keywords derived from LLM vocabulary—and jointly fine-tunes the model on term generation and recommendation to mitigate hallucinations and improve transferability.
Core Problem
Existing generative recommenders struggle with item identification: text-based methods suffer from hallucinations and ambiguity, while Semantic IDs (discrete codes) lack semantic meaning and require costly vocabulary expansion.
Why it matters:
- Hallucinations in text-based methods lead to recommending non-existent items, breaking system reliability
- Semantic IDs (SIDs) create a semantic gap with the LLM's pre-trained knowledge, hindering cross-domain generalization
- Current methods require expensive vocabulary resizing and alignment training to bridge the gap between IDs and natural language
Concrete Example:
Independent generation leads to inconsistent labeling (e.g., 'Cell-Phone' vs. 'Mobile-Phone' for identical features) or fails to distinguish models (assigning generic 'iPhone' to distinct versions). GRLM uses context to enforce consistency.
Key Novelty
Term IDs (TIDs) via Context-Aware Generation
- Represent items not as arbitrary numbers or raw titles, but as a fixed-length sequence of standardized, semantically rich keywords (Term IDs) derived from the LLM's native vocabulary
- Use 'Context-aware Term Generation' where the LLM sees an item's neighbors to ensure terms are consistent across similar items (resolving synonyms) but distinct enough to separate specific products
- Dual-track grounding (Direct + Structural Mapping) ensures generated text maps validly to real items even if the generation isn't an exact string match
Architecture
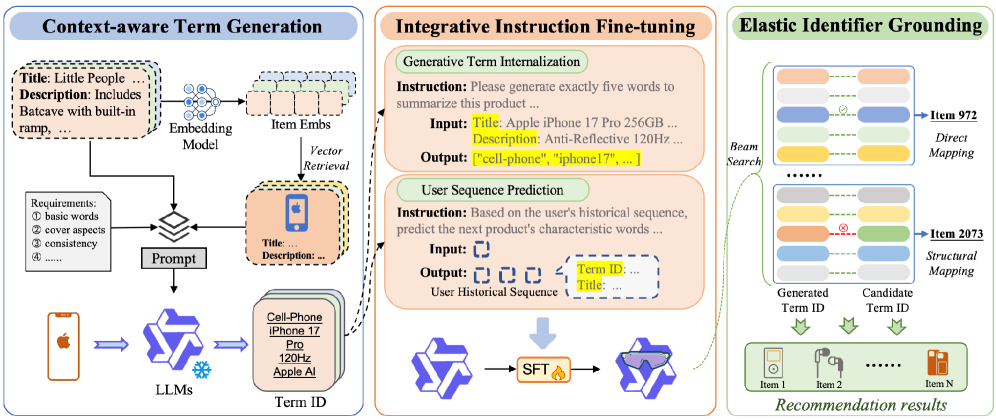
The three-stage pipeline of GRLM: Term Generation, Fine-tuning, and Grounding.
Evaluation Highlights
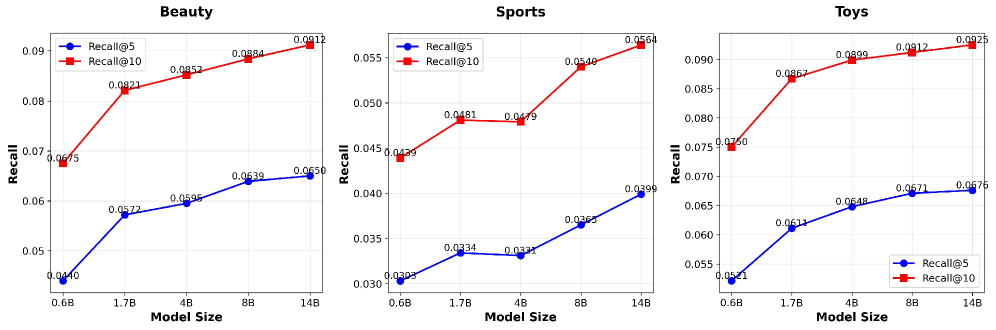
- +30.2% Recall@5 improvement on Sports dataset compared to the strongest baseline (OneRec-Think)
- Cross-domain Recall@K improves by >50% on average (e.g., Sports→Clothing) without specific alignment modules, leveraging natural language transfer
- Achieves >99% Valid Rate and Direct Hit Rate, effectively eliminating hallucination issues common in text-based generative recommendation
Breakthrough Assessment
8/10
Significantly outperforms SOTA by rethinking item tokenization. The shift from SIDs to semantic Term IDs solves the vocabulary gap and hallucination issues simultaneously, with strong scaling properties.