📝 Paper Summary
Radiology Report Generation (RRG)
Medical Multi-modal LLMs
LLM-RG4 adapts to diverse clinical inputs (single/multi-view, with/without history) via adaptive token fusion while reducing input-agnostic hallucinations through a new dataset and token-level loss weighting.
Core Problem
Current radiology report generation models assume fixed inputs (usually single-image) and hallucinate uninferable details (like prior comparisons) when that information is missing.
Why it matters:
- Clinicians adapt reports based on available data (e.g., comparing to prior exams if available), but models trained on fixed paradigms cannot flexibility adapt.
- Generating uninferable information (hallucination) like 'no change from prior' when no prior exists reduces clinical trust and safety.
- Existing methods to clean reports reduce information too drastically, while multi-view models fail when auxiliary inputs are missing.
Concrete Example:
A model trained on standard datasets might generate 'Heart size is stable compared to prior' even when provided with only a single frontal image and no historical record, because such phrases are common in training data but factually uninferable from the single input.
Key Novelty
LLM-RG4: Adaptive Fusion and Dataset Construction
- Creates a new dataset (MIMIC-RG4) using an LLM-based cyclic generation pipeline to ensure ground-truth reports perfectly match four specific input scenarios (e.g., removing comparisons if no prior history exists).
- Uses an Adaptive Token Fusion module to compress visual and textual history features into a fixed token count, allowing the LLM to handle varying inputs without structural changes.
- Employes a Token-Level Loss Weighting strategy that uses attribution maps to assign higher loss weights to positive or uncertain disease mentions, prioritizing clinical accuracy.
Architecture
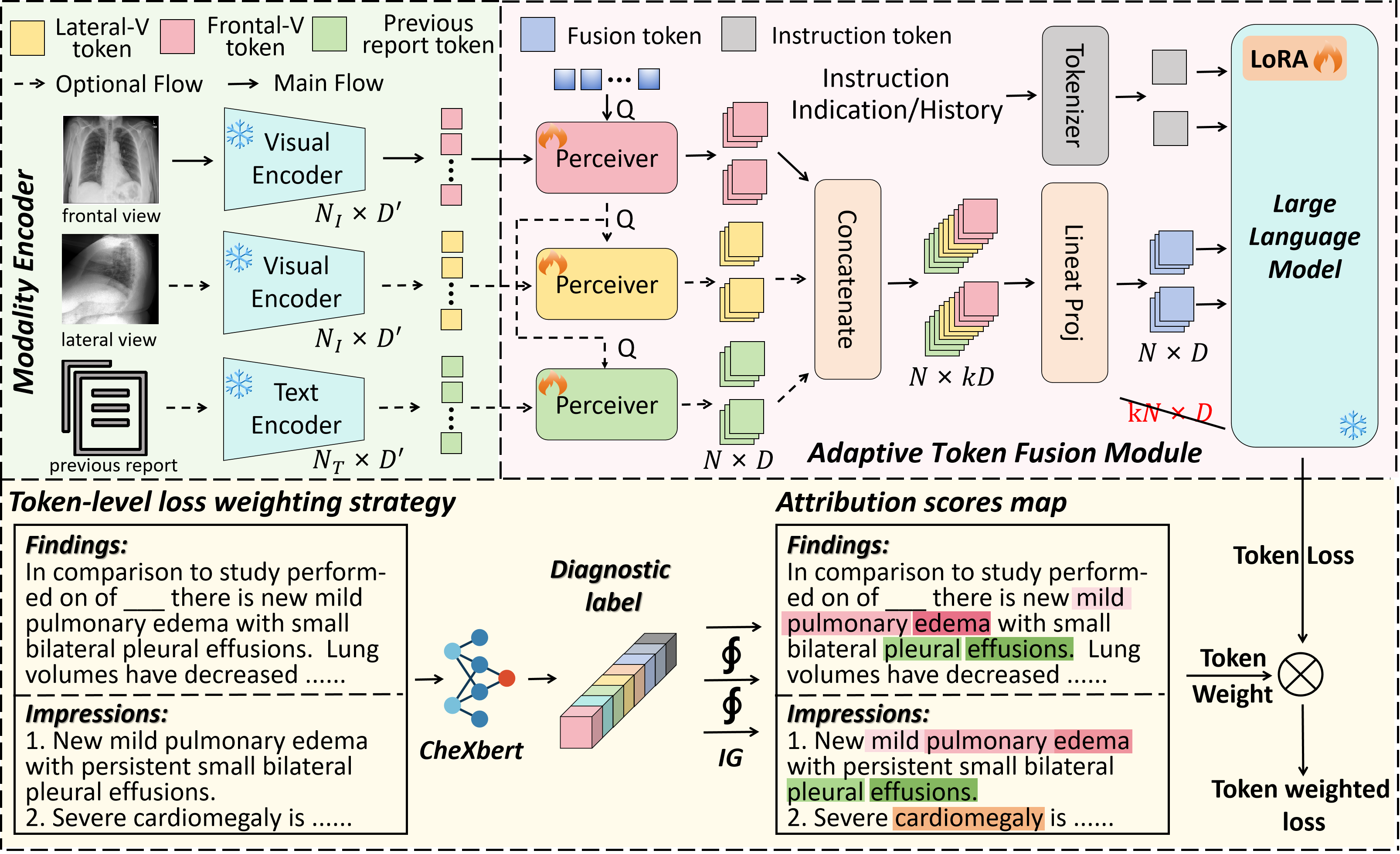
The overall architecture of LLM-RG4, illustrating the processing of multi-modal inputs (frontal, lateral, history) through the modality encoder, adaptive token fusion, and the LLM decoder with token-level loss weighting.
Evaluation Highlights
- Achieves state-of-the-art performance on MIMIC-RG4, outperforming baselines like X-rayGPT and Llava-Med in natural language generation metrics (e.g., +4.6% CIDEr on Single-View-No-Longitudinal).
- Significantly reduces input-agnostic hallucinations; DiscBERT evaluation shows hallucination rates drop to near zero on MIMIC-RG4 compared to high rates in standard MIMIC-CXR.
Breakthrough Assessment
8/10
Strong contribution in defining a pragmatic clinical problem (diverse inputs) and solving it with both a rigorously constructed dataset and a flexible architecture. Bridges the gap between rigid model paradigms and flexible clinical practice.