📝 Paper Summary
Memory recall
Evaluation methodology
MemSim creates reliable, diverse, and scalable memory evaluation datasets for LLM agents by simulating user profiles via a Bayesian network and generating causally consistent messages and questions.
Core Problem
Evaluating the long-term memory of LLM personal assistants is difficult because existing methods lack scalability (human annotation) or reliability (LLM-generated datasets suffer from hallucinations).
Why it matters:
- Manual annotation of user-agent message histories is expensive and unscalable
- Existing LLM-generated datasets often contain factual errors (ground truth correctness <90% generally, <40% in complex cases)
- Standard LLM generation lacks diversity, tending to produce only the most plausible user profiles
Concrete Example:
If a simulator generates a user message 'I am 30 years old', but then hallucinates an answer '25' to the question 'How old am I?', the evaluation dataset becomes invalid. Vanilla LLM generation frequently fails on aggregative questions like 'How many people are under 35?' due to such hallucinations.
Key Novelty
Bayesian-Causal Data Synthesis
- Uses a Bayesian Relation Network (BRNet) to model probabilistic dependencies between user attributes (e.g., age influences occupation), ensuring diverse and consistent profile sampling
- Separates the 'truth' generation (sampling structured hints from BRNet) from the 'text' generation (LLM rewriting), preventing the LLM from hallucinating facts during dataset creation
Architecture
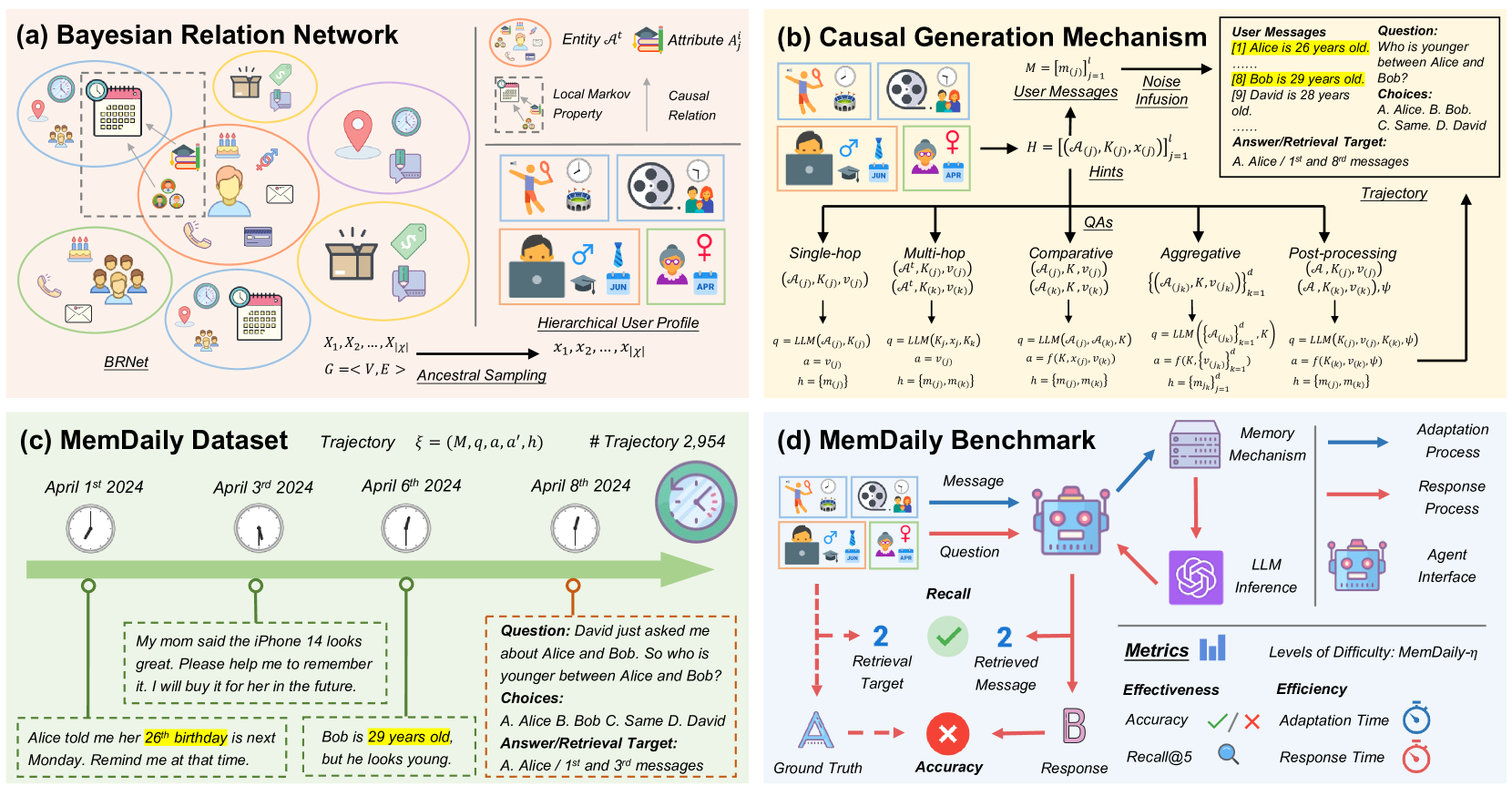
The MemSim pipeline: (a) Bayesian Relation Network for profile sampling, (b) Causal Generation Mechanism for creating consistent messages and QAs, (c) The resulting MemDaily dataset structure.
Evaluation Highlights
- Generated MemDaily dataset achieves >99% correctness on ground truth answers, significantly outperforming vanilla LLM generation (which drops below 40% on complex tasks)
- Maintains high diversity in user profiles compared to vanilla LLM methods, which suffer from mode collapse
- Provides a benchmark showing current LLMs (e.g., GPT-4) still struggle with aggregative and multi-hop memory retrieval tasks
Breakthrough Assessment
8/10
Addresses a critical bottleneck in agent evaluation (data reliability) with a theoretically grounded method (Bayesian networks). The resulting dataset appears highly robust compared to pure LLM generation.