📝 Paper Summary
Hallucination detection
Hallucination mitigation
Finch-Zk improves hallucination management by checking consistency across diverse model architectures and applying targeted corrections only to specific problematic segments without rewriting accurate content.
Core Problem
Current zero-knowledge hallucination safeguards struggle with single-model biases (consistent but wrong outputs) and coarse mitigation techniques that rewrite entire responses, often corrupting accurate information.
Why it matters:
- RAG-based checks require knowledge bases that are often unavailable or privacy-restricted in enterprise settings
- Single-model consistency checks (like SelfCheckGPT) fail when a model is confidently wrong due to inherent architectural biases
- Whole-response rewriting for mitigation is inefficient and risks altering correct information, lacking the precision needed for high-stakes domains
Concrete Example:
If a model hallucinates one sentence in a long biography, existing methods might rewrite the whole paragraph, potentially introducing new errors. Finch-Zk isolates that single sentence, checks it against other models (e.g., Llama vs. Claude), and corrects only that sentence.
Key Novelty
Finch-Zk (Fine-grained Cross-model consistency)
- Generates diverse samples using different model architectures (e.g., Llama, Claude) and prompt variations (e.g., CoT, rephrasing) to expose 'confident' hallucinations that single models hide
- Splits responses into semantic blocks and uses a weighted scoring system to pinpoint specific hallucinated sentences rather than flagging the whole text
- Mitigates errors via a two-stage process: first correcting only the specific bad blocks, then smoothing the full response for coherence
Architecture
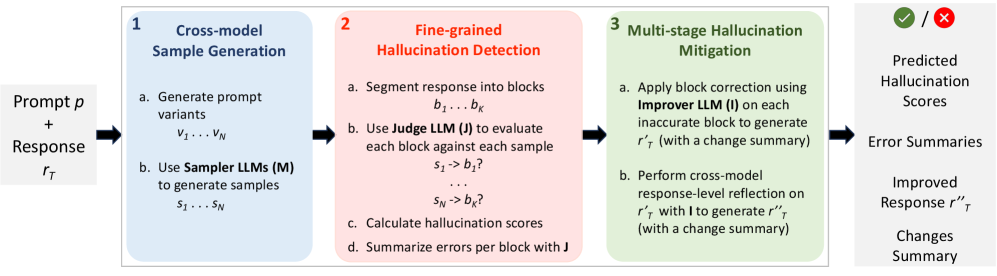
The three-stage workflow of Finch-Zk: Sampling, Detection, and Mitigation.
Evaluation Highlights
- +6-39% improvement in F1 scores for hallucination detection on the FELM dataset compared to state-of-the-art baselines like SelfCheckGPT
- +12.6 percentage points increase in answer accuracy on GPQA-diamond for Llama 4 Maverick using the full Finch-Zk pipeline
- Outperforms RAG-based detection (which uses external knowledge) by ~17% F1 score on FELM, demonstrating strong zero-knowledge capabilities
Breakthrough Assessment
8/10
Significant practical advance in 'zero-knowledge' safety. Demonstrates that cross-model consistency is a viable substitute for external knowledge bases, with a highly effective surgical correction mechanism.