📝 Paper Summary
Theoretical Understanding of LLMs
Scaling Laws
Data Compression and Prediction
The paper explains LLM scaling laws, knowledge acquisition order, and hallucinations by modeling training as a compression process where models learn ubiquitous syntax first and rare knowledge later, bounded by capacity.
Core Problem
Despite the empirical success of Large Language Models (LLMs), there is a lack of principled theoretical explanations for their scaling laws, the emergence of hallucinations, and the specific order in which they acquire different types of information (syntax vs. knowledge).
Why it matters:
- Understanding *why* scaling laws hold is crucial for predicting future model performance and resource requirements.
- Identifying the mechanism behind hallucinations (compression artifacts) can inform better training strategies to mitigate them.
- Traditional learning theory frameworks fail to fully explain phenomena like in-context learning or the specific dynamics of knowledge acquisition.
Concrete Example:
When an LLM is trained on limited data or with limited capacity, it might perfectly generate grammatically correct sentences (syntax) but hallucinate facts about rare entities (knowledge). Current theories don't quantitatively explain why the syntax is learned before the rare facts, or why the model confidently generates the wrong fact instead of abstaining.
Key Novelty
Syntax-Knowledge Model via Kolmogorov Compression
- Views LLM training as a two-part code optimization: minimizing the model description length plus the data's compressed length (log-likelihood).
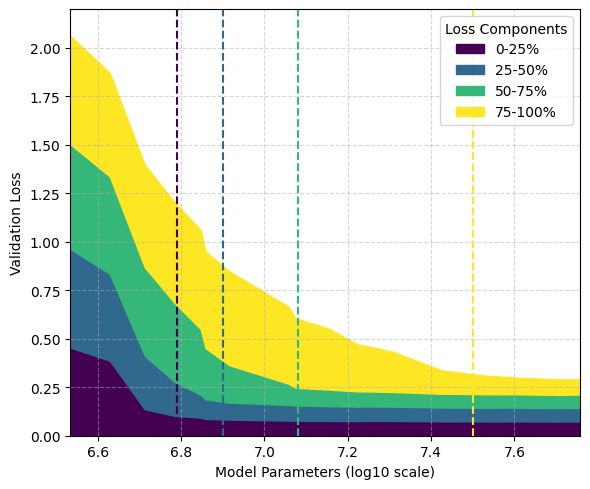
- Proposes a hierarchical generative model separating 'Syntax' (parametric, learns fast) from 'Knowledge' (non-parametric, power-law distributed), reflecting Zipf's and Heap's laws.
- Demonstrates that hallucinations are inevitable compression artifacts when model capacity is insufficient to encode rare knowledge tail events.
Architecture
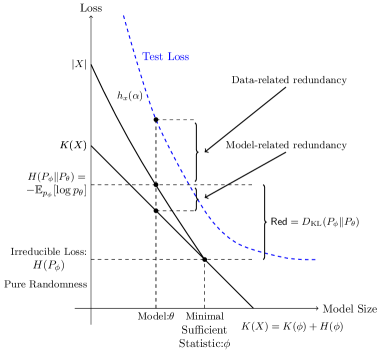
A schematic of the Kolmogorov Structure Function (a) and the proposed Syntax-Knowledge Data Generation Model (b).
Evaluation Highlights
- Theoretically derives an upper bound for data scaling laws: O(1/N^(1-α) + 1/N) + H, where α is the Zipfian discount parameter, matching empirical observation.
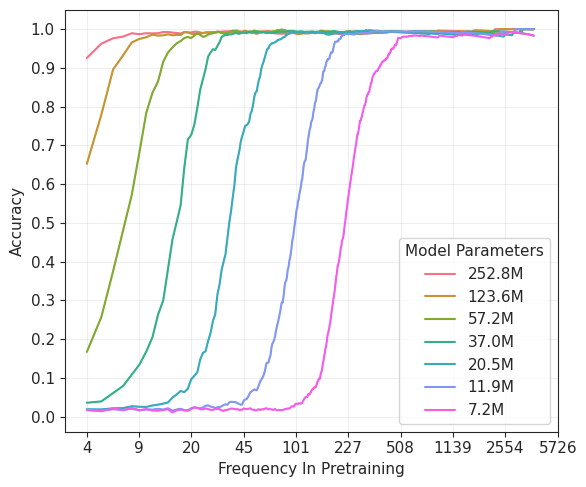
- Experimentally validates that models learn syntax patterns significantly faster than factual knowledge, which is acquired strictly according to frequency rank.
- Shows that 'hallucinations' occur on knowledge elements that are frequent enough to be attempted but too rare to be perfectly memorized under capacity constraints.
Breakthrough Assessment
8/10
Provides a strong theoretical grounding for empirical scaling laws using Kolmogorov complexity. The Syntax-Knowledge decomposition offers a clean, intuitive explanation for why LLMs hallucinate and how they learn.