📊 Experiments & Results
Evaluation Setup
Comparison against standard English and Indic baselines
Benchmarks:
- English Benchmarks (General Language Understanding (16 tasks))
- Indic Language Benchmarks (Multilingual proficiency)
Metrics:
- Average score (English benchmarks)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| English Benchmarks (Average of 16 tasks) | Average Score | 0.55 | 0.57 | +0.02 |
| Adversarial/Factual queries | Hallucination Rate (Pre-Factual SFT) | 0 | 33 | +33 |
Experiment Figures
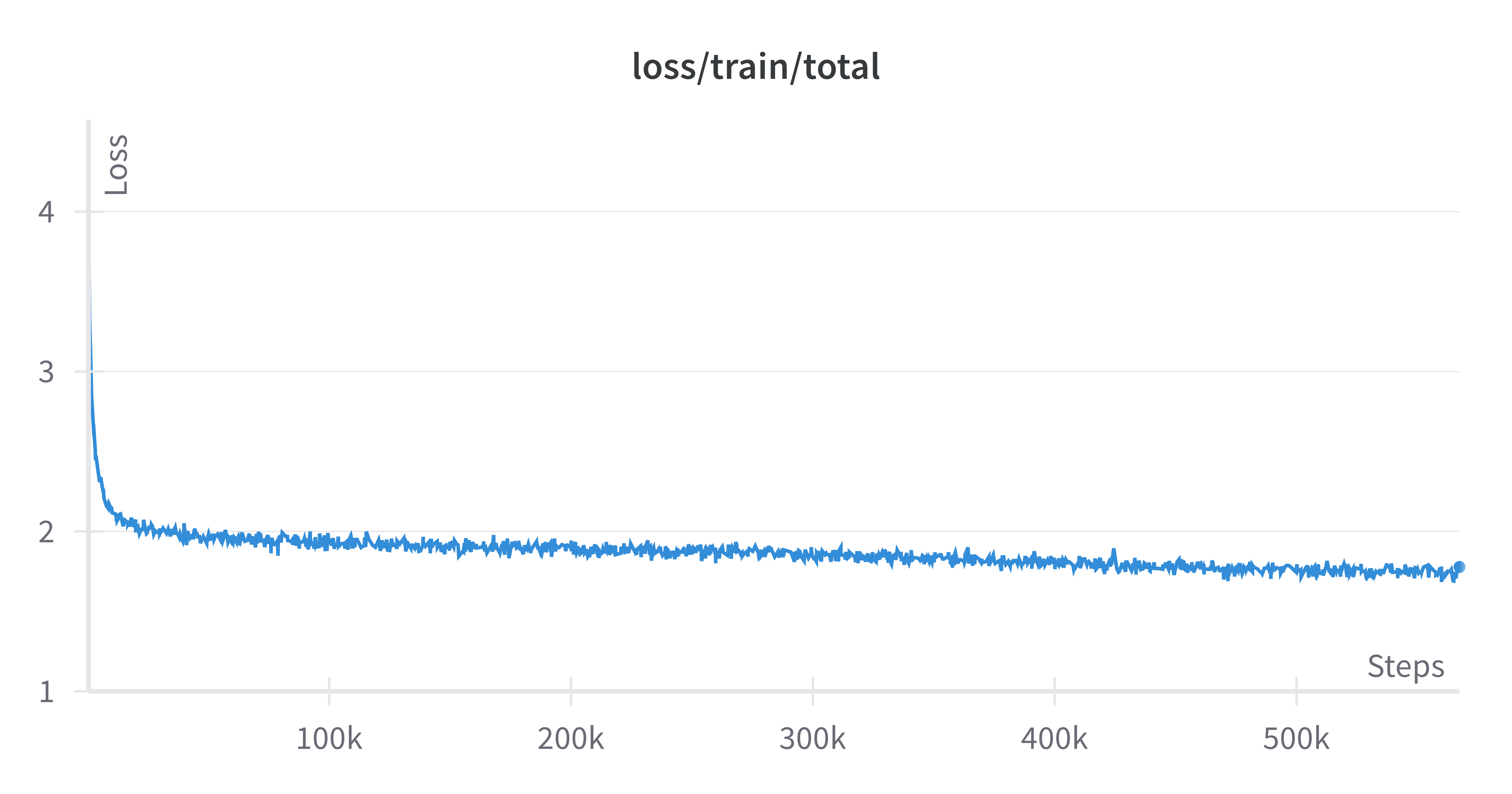
Training loss curve during pre-training
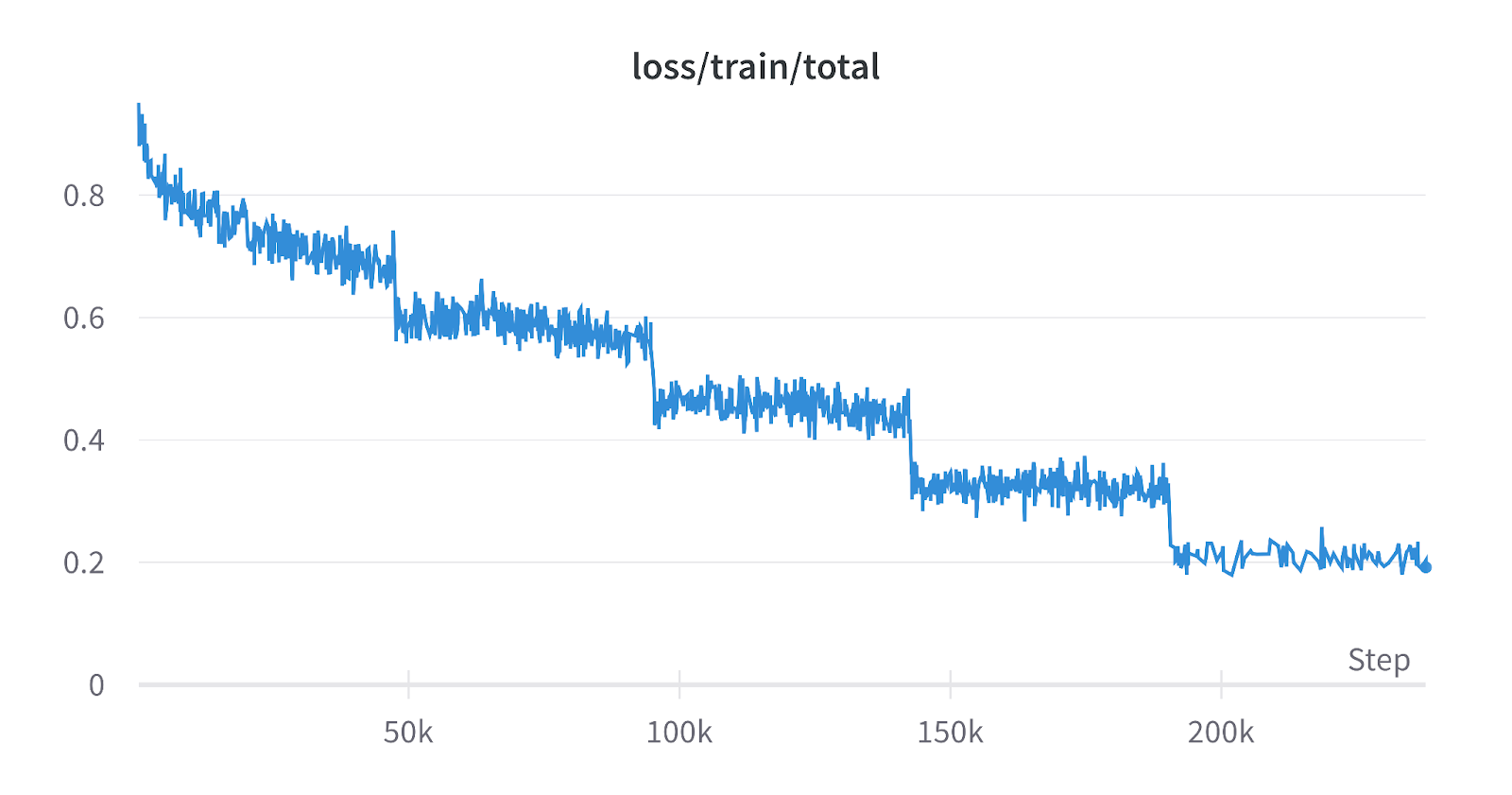
Training loss curve during Supervised Fine-Tuning (SFT)
Main Takeaways
- Krutrim matches or slightly exceeds Llama-2 on English tasks despite being optimized for multilingual/Indic contexts.
- The use of a custom tokenizer and extensive Indic pre-training data is pitched as the primary driver for performance parity/gains.
- Direct Preference Optimization (DPO) was essential for aligning the model with safety guidelines and reducing hallucinations.