📝 Paper Summary
LLM Alignment
Reinforcement Learning from Human Feedback (RLHF)
This survey provides a structured taxonomy and detailed review of LLM alignment techniques, categorizing methods by reward modeling, feedback types, RL strategies, and optimization approaches.
Core Problem
LLMs pretrained on vast corpora often generate undesired, toxic, or untruthful responses because their next-token prediction objective does not inherently align with human values.
Why it matters:
- Unaligned models can provide harmful instructions (e.g., how to commit illegal activities) or toxic content, posing safety risks.
- The rapid proliferation of alignment techniques (RLHF, DPO, RLAIF) lacks a comprehensive survey that categorizes and compares them systematically.
- Without alignment, even powerful models like GPT-4 would fail to reliably follow user intent or maintain helpfulness and honesty.
Concrete Example:
A base LLM might respond to a query about 'how to make a bomb' with detailed instructions because it saw such data during training. An aligned model, trained via RLHF to value safety, would refuse the request or pivot to a safe educational topic.
Key Novelty
Taxonomy of 13 Categorical Directions for Alignment
- Decomposes alignment into four pillars: Reward Model (explicit vs. implicit), Feedback (preference vs. binary, human vs. AI), RL (reference-based vs. free), and Optimization (online vs. offline).
- Introduces a structured comparison framework to evaluate widely used methods like PPO, DPO, and RLAIF against 13 specific metrics (e.g., point vs. preference reward, length control).
- Clarifies the evolution from standard RLHF (explicit reward modeling) to direct preference optimization (DPO, implicit reward) and AI-driven feedback (RLAIF).
Architecture
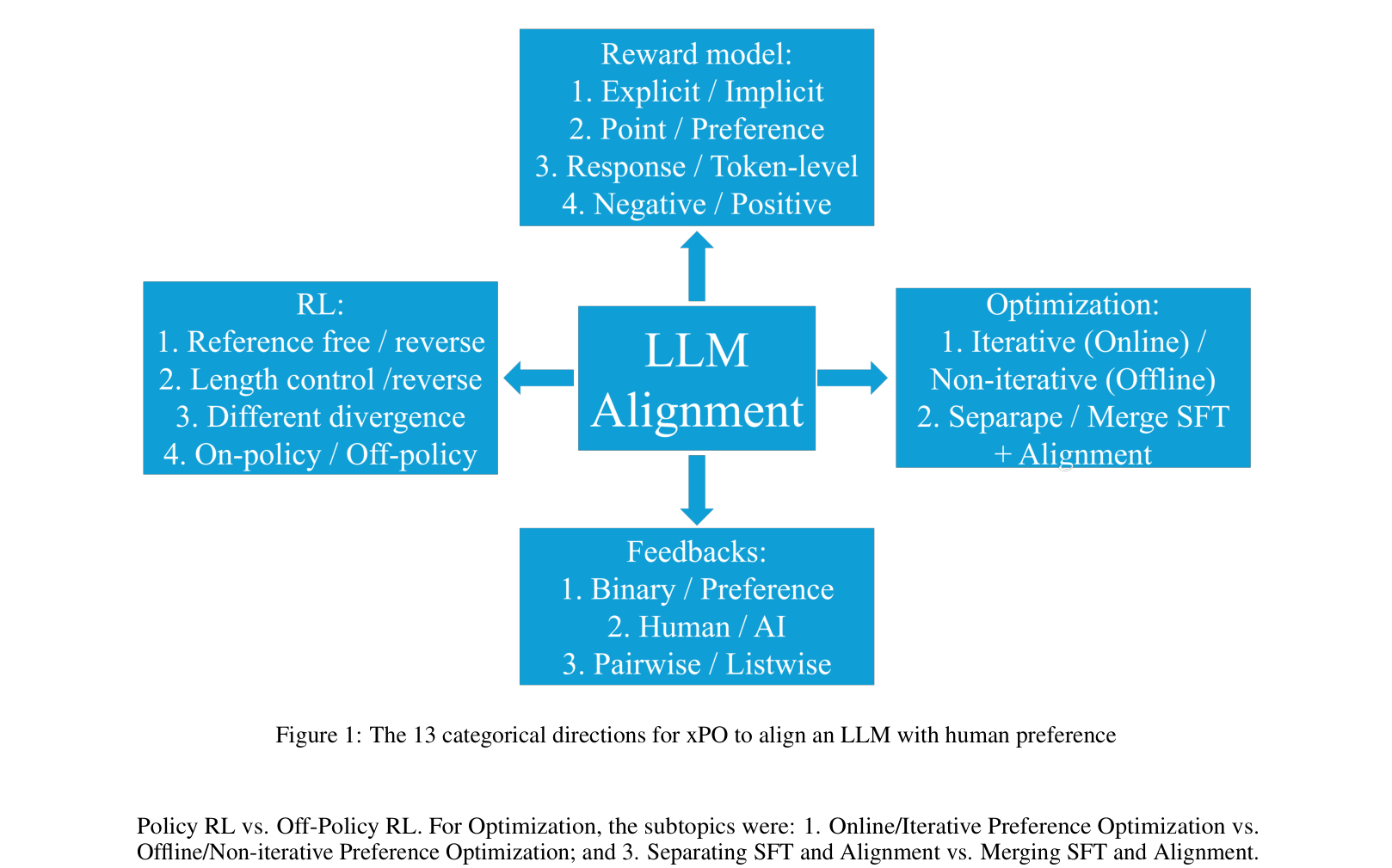
A hierarchical taxonomy of the 13 categorical directions for aligning LLMs with human preference.
Evaluation Highlights
- InstructGPT (1.3B) outputs were preferred over 175B GPT-3 outputs, demonstrating that alignment can be more impactful than scale.
- RLAIF achieved comparable performance to RLHF in summarization and helpful dialogue tasks while outperforming RLHF on harmlessness benchmarks.
- RSO (Rejection Sampling Optimization) outperformed SLiC and DPO on summarization and dialogue tasks using a T5-large model.
Breakthrough Assessment
9/10
A highly necessary and comprehensive survey that organizes a chaotic and rapidly evolving field. It provides critical clarity on the relationships between disparate methods like PPO, DPO, and RLAIF.