📝 Paper Summary
Hallucination detection
Internal representations
Error analysis
LLMs encode truthfulness highly locally in exact answer tokens, allowing probing classifiers to detect errors and specific error types better than aggregation methods, though these signals do not generalize across distinct skills.
Core Problem
Existing hallucination detection methods often rely on extrinsic behavior or suboptimal internal signals (like aggregating logits across all tokens), failing to capture the rich, localized truthfulness information encoded within the model.
Why it matters:
- Current detection methods miss crucial signals by inspecting the wrong tokens (e.g., last token of prompt or random generated tokens)
- Understanding *where* and *how* truthfulness is encoded is essential for building reliable error detectors without external tools
- Previous assumptions about 'universal truthfulness' directions may be flawed, risking the deployment of detectors that fail on new tasks
Concrete Example:
In the sentence 'The capital of Connecticut is Hartford...', standard methods might average probabilities over the whole sentence or check the last token. This paper shows the truthfulness signal is concentrated specifically in the token 'Hartford'; probing elsewhere misses the signal, leading to lower detection accuracy.
Key Novelty
Exact-Answer Token Probing for Hallucination
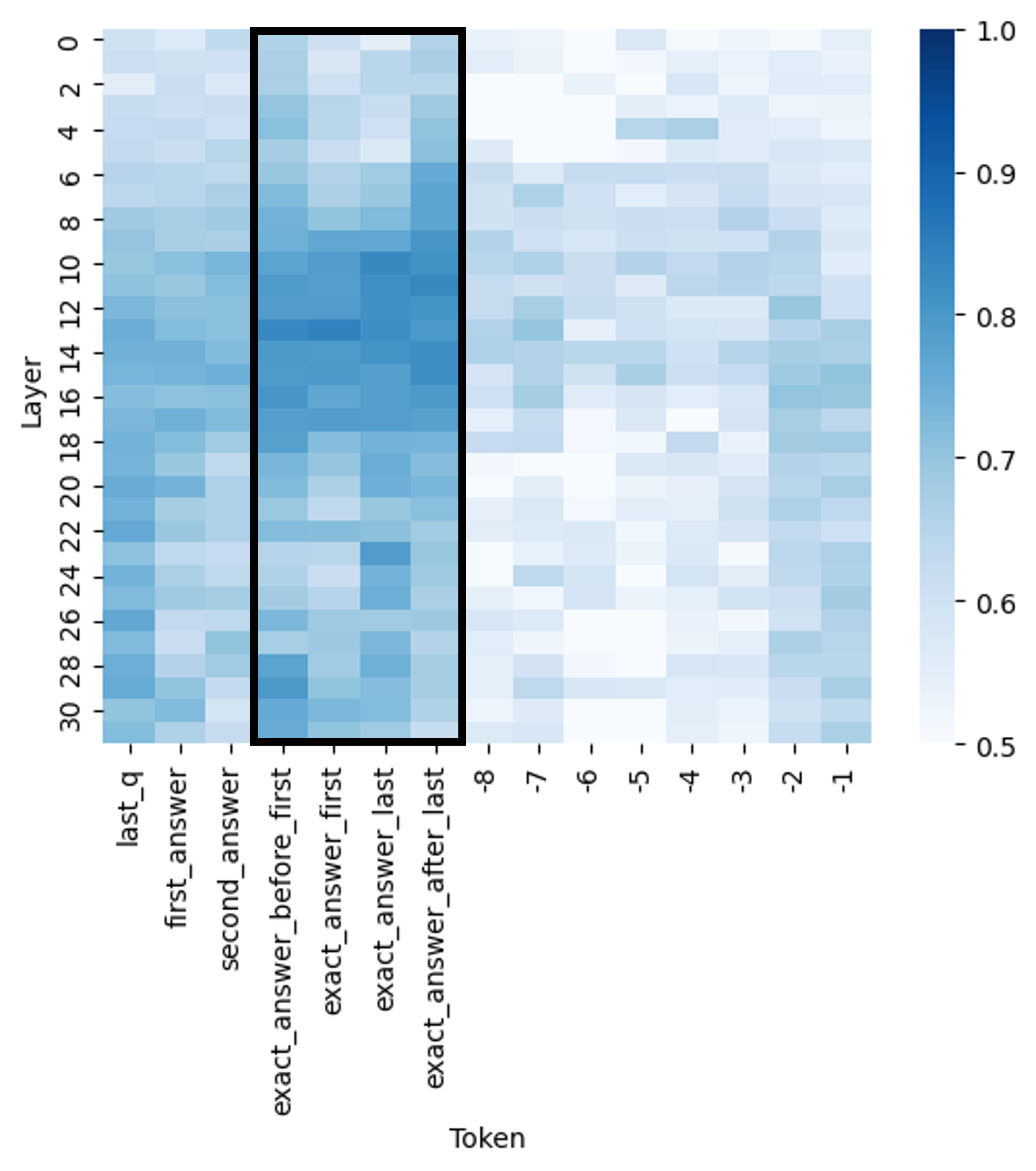
- Identifies that truthfulness information is spatially concentrated in the 'exact answer' tokens of a generation, rather than being spread evenly or located at the end
- Demonstrates that linear classifiers trained on these specific token representations can predict not just correctness, but specific *types* of errors (e.g., consistent misconceptions vs. random noise)
- Reveals a 'knowing-saying' gap where the model's internal representation classifies an answer as correct, yet the model explicitly generates the wrong answer
Architecture

Illustration of token selection strategies for error detection in long-form generation
Evaluation Highlights
- Probing exact answer tokens outperforms logit-based baselines (Logits-min, P(True)) across almost all 10 datasets (e.g., +5-10% AUC improvements on TriviaQA/HotpotQA)
- Truthfulness probes generalize within skills (e.g., QA to QA) but fail completely across skills (e.g., QA to Sentiment Analysis), challenging the 'universal truthfulness' hypothesis
- Probing classifiers can distinguish between error types (e.g., 'consistent error' vs. 'occasional error') with high accuracy, which logit baselines cannot do
Breakthrough Assessment
7/10
Strong empirical evidence refining *where* to look for truthfulness (exact answer tokens) and debunking the universality of truth directions. High practical value for error detection.