📝 Paper Summary
Agentic RAG pipeline
Reasoning Distillation
Agent Distillation transfers interactive tool-use capabilities from large language models to smaller ones by training them on reason-act-observe trajectories rather than static reasoning traces.
Core Problem
Standard chain-of-thought (CoT) distillation teaches small models to mimic reasoning traces but fails to impart the ability to interact with external tools or verify computations.
Why it matters:
- Small models often hallucinate facts or fail at precise arithmetic when relying solely on internal weights via CoT
- Naive distillation of reasoning traces does not generalize well to out-of-distribution tasks requiring new knowledge or complex calculations
- Existing methods focus on distilling static reasoning, missing the dynamic 'agentic' behavior (acting and observing) crucial for solving complex real-world problems
Concrete Example:
For the question 'What would $100 invested in Apple stock in 2010 be worth by 2020?', a CoT-distilled model might hallucinate the stock price or miscalculate the multiplication. An agent-distilled model would generate Python code to retrieve the stock history and perform the calculation exactly.
Key Novelty
Agent Distillation with First-Thought Prefix and Self-Consistent Action Generation
- Trains small models on interactive 'Thought -> Action -> Observation' trajectories (using code/retrieval tools) instead of static text-only reasoning traces
- Aligns the teacher's agentic behavior with its internal reasoning strengths by forcing the first agent thought to match a standard Chain-of-Thought step (First-Thought Prefix)
- Enhances test-time robustness by sampling multiple action candidates and selecting the one that executes successfully and produces consistent outputs (Self-Consistent Action Generation)
Architecture
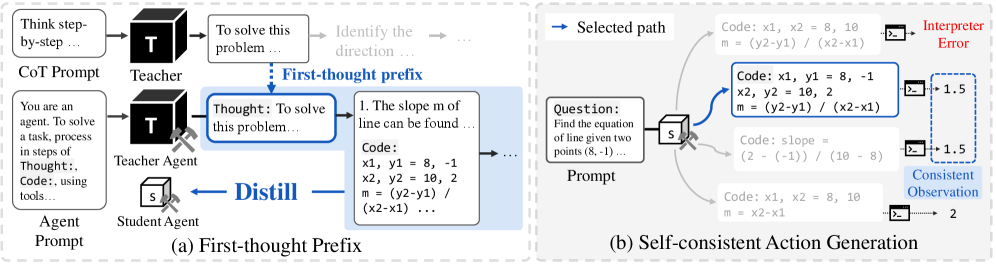
Overview of the two proposed methods: First-Thought Prefix (FTP) for teacher trajectory generation and Self-Consistent Action Generation (SAG) for student inference.
Evaluation Highlights
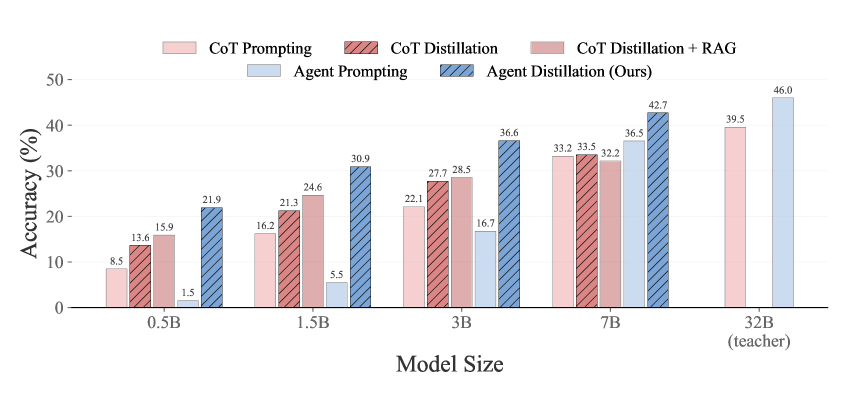
- Distilled 0.5B, 1.5B, and 3B agent models achieve performance comparable to next-tier larger (1.5B, 3B, 7B) CoT-distilled models on average
- 7B Agent model outperforms the teacher-sized 32B CoT model on average across 8 reasoning benchmarks
- Significant gains on out-of-domain mathematical tasks: 1.5B agent matches 3B CoT performance on benchmarks like GSM-Hard and OlymMATH
Breakthrough Assessment
8/10
Strong empirical evidence that distilling interactive behavior (agency) is more parameter-efficient than distilling static reasoning (CoT), enabling very small models to solve complex tasks.