📝 Paper Summary
Factuality in Clinical NLP
Hallucination suppression
VeriFact is an automated system that checks the factual accuracy of clinical text against a patient's electronic health record, achieving agreement with human ground truth comparable to inter-clinician agreement.
Core Problem
Clinicians cannot efficiently verify LLM-generated clinical text due to the 'needle-in-a-haystack' challenge of checking facts against massive longitudinal Electronic Health Records (EHRs).
Why it matters:
- LLMs are increasingly used to summarize patient records, but hallucinations in medical contexts can be dangerous
- Manual verification by clinicians is too time-consuming to be scalable
- Existing benchmarks focus on general medical knowledge (QA exams) rather than patient-specific grounded fact-checking against EHR data
Concrete Example:
An LLM might write 'patient underwent a transthoracic echocardiogram which showed no orbital cellulitis.' A clinician must dig through cardiology and ophthalmology notes to find this is a hallucination (an echo cannot see orbital cellulitis). VeriFact automates this retrieval and verification.
Key Novelty
VeriFact: Patient-Specific EHR Fact-Checking via Atomic Proposition Decomposition
- Decomposes clinical narratives into atomic propositions (simple Subject-Object-Predicate statements) based on logical atomism
- Retrieves relevant facts from the patient's entire longitudinal EHR using RAG to create a dynamic reference context
- Uses an LLM-as-a-Judge to verify if each proposition is 'Supported', 'Not Supported', or 'Not Addressed' by the retrieved context
Architecture
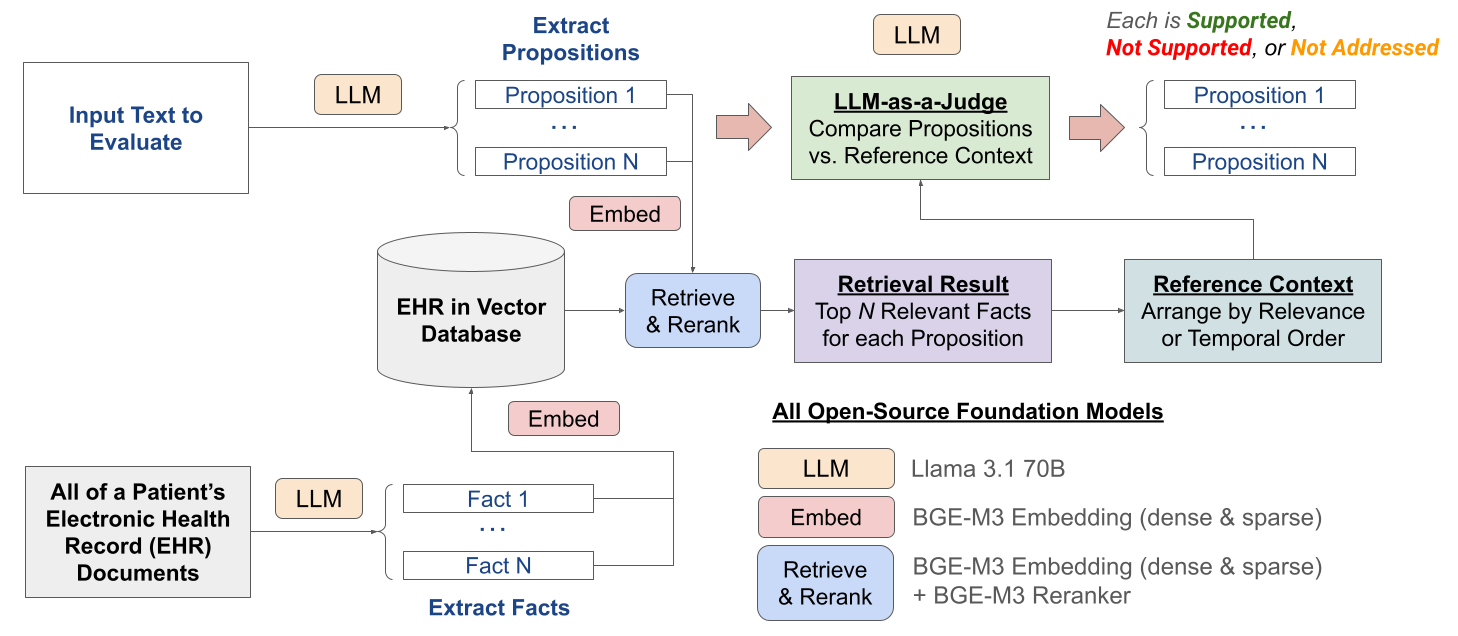
The VeriFact pipeline: Input Text -> Decomposition (Sentences/Atomic Claims) -> Retrieval (from EHR Vector DB) -> Verification (LLM-as-a-Judge) -> Verdict.
Evaluation Highlights
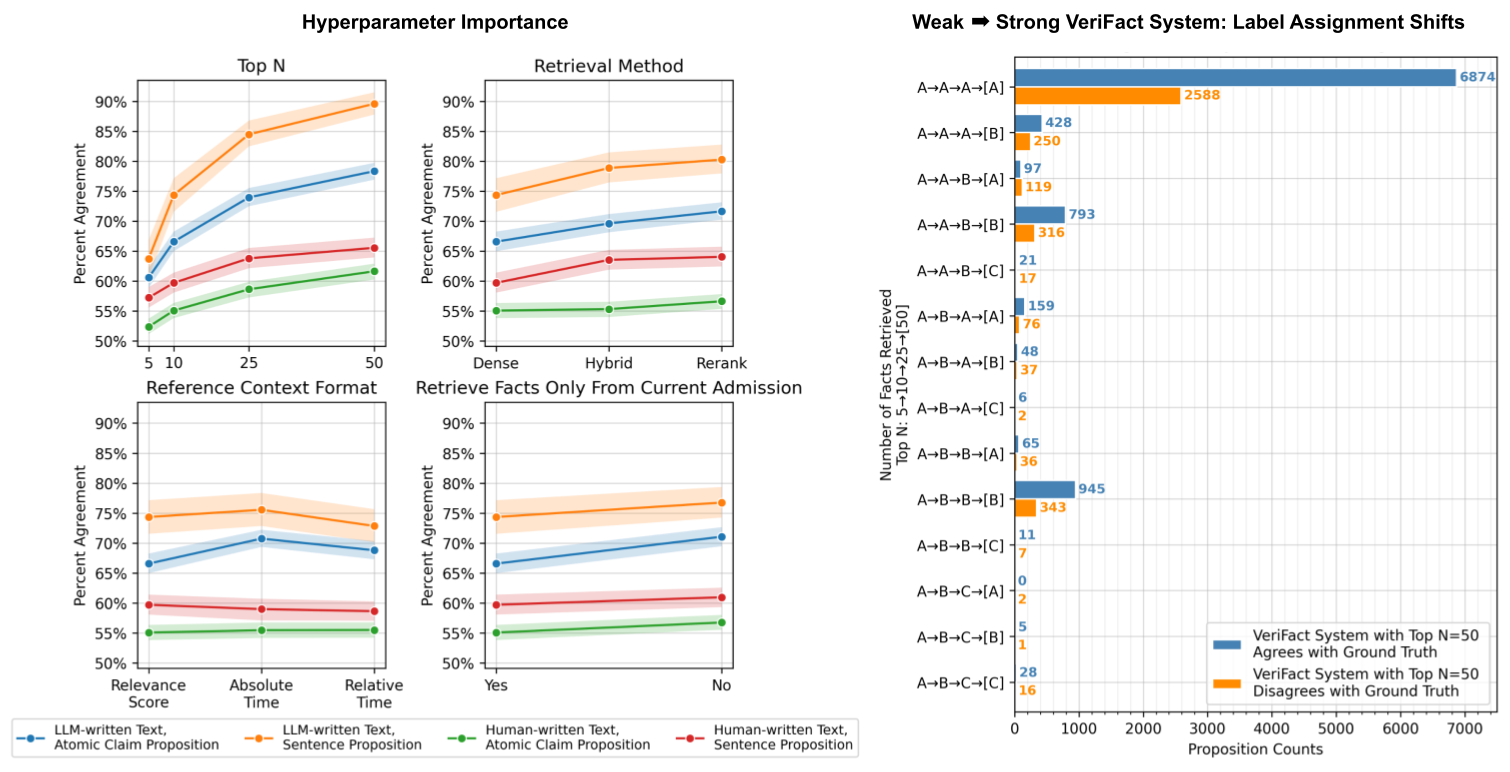
- Achieves 92.7% agreement with human ground truth on sentence propositions for LLM-written summaries (comparable to human-human agreement)
- Releases VeriFact-BHC, a dataset of 13,290 clinician-annotated statements from 100 MIMIC-III patients
- Atomic claim extraction reduces invalid propositions to 0.4% compared to 19.8% for simple sentence splitting in human-written notes
Breakthrough Assessment
8/10
Significant contribution to clinical NLP by providing both a strong baseline system that matches human performance and a high-quality, expert-annotated benchmark dataset for a critical, under-explored problem (patient-specific factuality).