📝 Paper Summary
Legal Question Answering
Hallucination Mitigation
Benchmark Construction
This paper introduces a legal hallucination benchmark and a two-stage fine-tuning method combining behavior cloning with hard sample-aware iterative Direct Preference Optimization to improve statute citation accuracy.
Core Problem
General and specialized LLMs frequently hallucinate in legal contexts, fabricating statutes or providing irrelevant citations, and lack dedicated metrics to measure these specific errors.
Why it matters:
- High-stakes legal domains require precise interpretation; fabricated laws or incorrect advice can have severe real-world consequences.
- Existing legal LLMs (e.g., LawGPT, LexiLaw) still produce misleading responses, and general benchmarks fail to capture specific legal hallucination types like 'Non-existent Statute' or 'Irrelevant Statute'.
- Manual annotation of legal hallucinations is prohibitively expensive and requires domain expertise.
Concrete Example:
When asked about a specific legal scenario, GPT-4o-mini might cite a 'Section 302' of a law when it should be 'Section 303' (Wrong Number), or invent an 'Article 15 on Data Privacy' that does not exist (Non-existent Statute), leading to invalid legal advice.
Key Novelty
Hard Sample-aware Iterative DPO (HIPO) & LegalHalBench
- HIPO iteratively filters training data by removing 'easy' samples (where the model already cites statutes correctly), forcing the model to learn from increasingly difficult negative examples.
- LegalHalBench is the first benchmark specifically categorizing five distinct types of legal hallucinations (e.g., Wrong Statute Name, Irrelevant Statute) with automated metrics to detect them.
- Uses a two-step automated data curation pipeline involving GPT-4-turbo to generate high-quality questions and answers grounded in actual legal provisions, reducing manual annotation costs.
Architecture
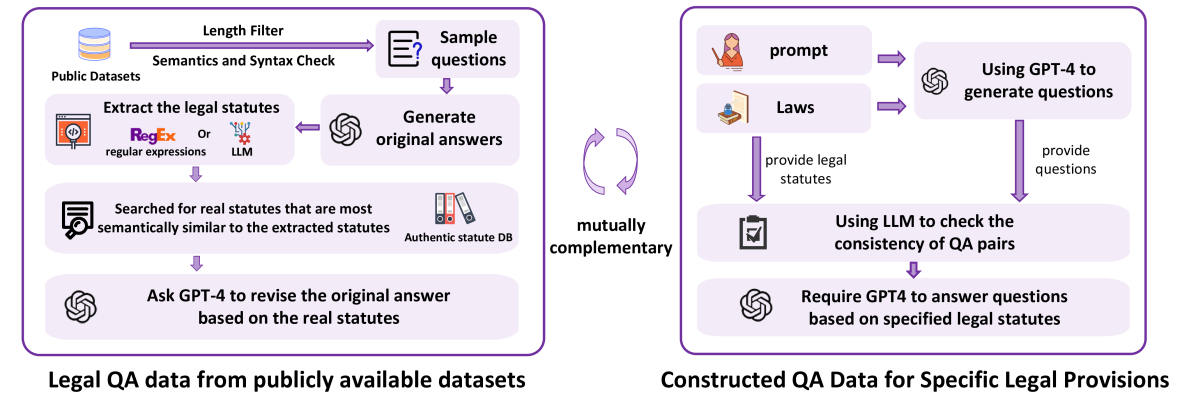
The overall framework including the automated dataset curation pipeline and the two-stage training process (SFT + HIPO).
Evaluation Highlights
- Achieves 38.35% Non-Hallucinated Statute Rate (NHSR), significantly outperforming GPT-4o (29.28%) and Llama-3-8B-Instruct (13.63%).
- Improves Statute Relevance Rate by 37.13% compared to the vanilla base model.
- Achieves a dominant win rate in helpfulness evaluation against existing legal LLMs (LawGPT, LexiLaw) and general models.
Breakthrough Assessment
7/10
Strong contribution in domain-specific hallucination definition and benchmarking. The HIPO method is a solid advancement in preference learning, though the core innovation is the application logic rather than a new fundamental architecture.