📝 Paper Summary
LLM-as-a-Judge
Bias in automated evaluation
By testing on verifiable benchmarks like math and code, this study reveals that stronger models prefer their own outputs primarily because those outputs are objectively better, not just due to bias.
Core Problem
Prior research shows LLMs favor their own outputs during evaluation (self-preference bias), but relying on subjective tasks makes it impossible to know if this preference is a harmful error or a correct judgment of superior quality.
Why it matters:
- If self-preference is purely bias, using LLMs for benchmarking or self-refinement is unreliable and unfair
- Previous studies on subjective tasks (summarization, chat) lack ground truth, leaving the nature of this bias ambiguous
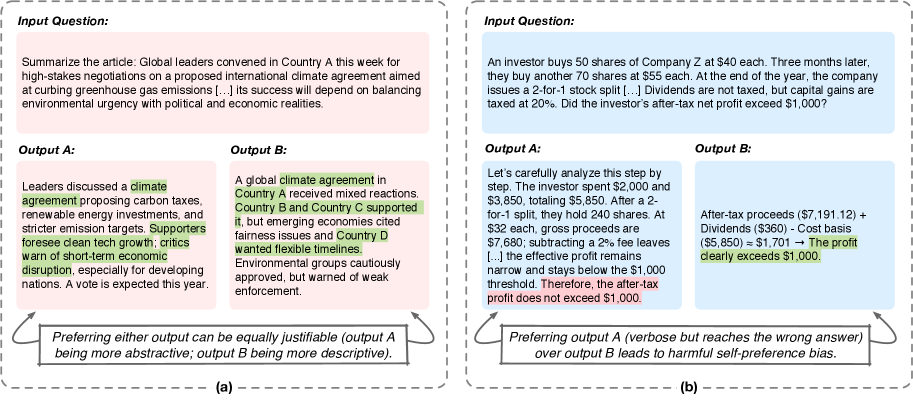
Concrete Example:
When an LLM evaluator is asked to judge two responses—one correct one generated by itself and one incorrect one from another model—it should prefer itself. Conversely, if it generates a wrong answer but prefers it over a correct peer answer, that is harmful bias. Subjective chat benchmarks cannot distinguish these cases.
Key Novelty
Verifiable Ground-Truth Analysis of Self-Preference
- Evaluates self-preference on objective tasks (Math, Code, Facts) where correctness is verifiable, allowing separation of 'legitimate' preference (preferring self because self is right) from 'harmful' preference (preferring self despite being wrong)
- Systematically compares 11 evaluator models against a fixed set of 7 evaluatee models to standardize the measurement of bias across model scales
Architecture
Conceptual comparison between previous subjective studies and this paper's objective framework.
Evaluation Highlights
- Task accuracy and judge accuracy are strongly correlated (r > 0.70 across MATH500, MMLU, MBPP+), confirming better generators are better evaluators
- Llama-3-70B achieves 95.16% Legitimate Self-Preference Ratio (LSPR) on MATH500, indicating its self-preference is almost entirely justified by objective quality
- Stronger models exhibit more harmful self-preference when they do err: incorrect strong models prefer their own wrong answers more often than weaker models do
Breakthrough Assessment
7/10
Provides a crucial nuance to the 'self-preference is bad' narrative by proving it is largely legitimate in strong models, though the method is an analysis framework rather than a new model architecture.