📝 Paper Summary
Memory in LLMs
Agent evaluation
MemBench is a comprehensive benchmark for evaluating LLM agents' memory that introduces reflective memory tasks and distinct observation versus participation scenarios to better mirror real-world agent usage.
Core Problem
Existing memory evaluations for LLM agents are limited to factual recall in direct participation scenarios, neglecting high-level reflective reasoning (inferring preferences) and passive observation scenarios.
Why it matters:
- Real-world agents must not only recall explicit facts but also infer implicit user preferences (reflective memory) to provide personalized assistance.
- Agents often operate in observation modes (passively recording user streams) which differ fundamentally from participation modes (active dialogue) where the agent's own responses pollute the context.
- Current metrics focus on effectiveness (accuracy) while ignoring efficiency (time cost) and capacity limits, which are critical for deployment.
Concrete Example:
A user might say "I love spicy food" (factual). Later, they might praise specific dishes like "Sichuan hotpot" and "Mapo Tofu." Current benchmarks test if the agent remembers "Sichuan hotpot," but fail to test if the agent infers the high-level preference "User likes Sichuan cuisine" (reflective), which is crucial for future recommendations.
Key Novelty
Multi-Level, Multi-Scenario Memory Evaluation Framework
- Introduces 'Reflective Memory' as a distinct evaluation tier: testing the agent's ability to abstract high-level preferences (e.g., taste in movies) from low-level behaviors, rather than just recalling explicit facts.
- Distinguishes between 'Participation' (interactive dialogue) and 'Observation' (passive message stream) scenarios to isolate memory capabilities from the agent's generation/reasoning modules.
- Constructs a massive dataset using user relation graphs derived from real recommendation datasets (MovieLens, Food, Goodreads) to ensure realistic preference distributions.
Architecture
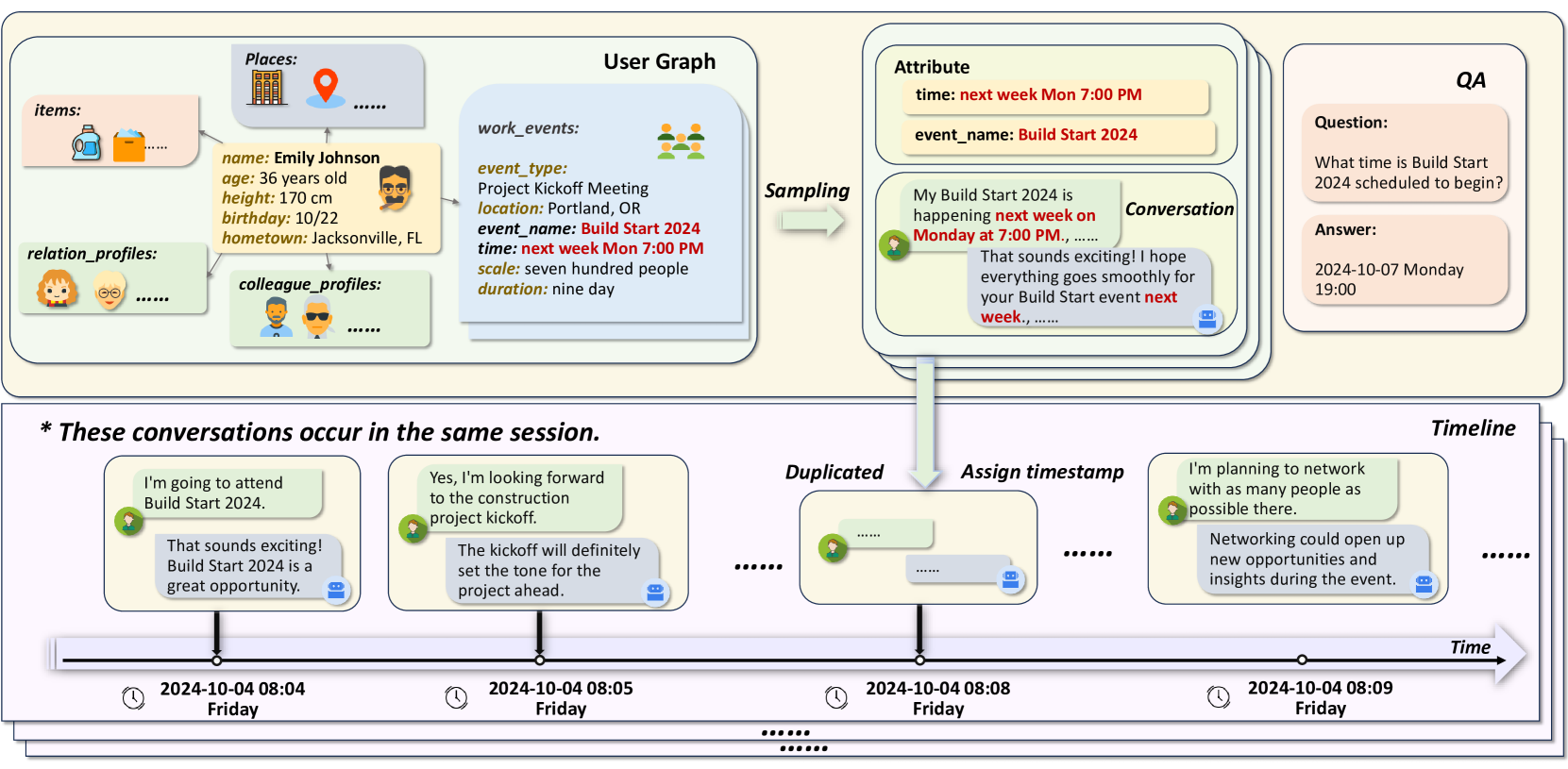
The data construction pipeline for MemBench.
Evaluation Highlights
- Traditional memory mechanisms like MemoryBank and GenerativeAgent struggle significantly with reflective memory compared to factual memory.
- Vector-retrieval based memory shows a sharp decline in performance as memory context length increases, revealing capacity limitations not seen in full-context models.
- The benchmark includes over 500 user profiles and scales up to 100k tokens per test session to stress-test long-term memory limits.
Breakthrough Assessment
7/10
Strong contribution in formalizing 'reflective memory' and 'observation scenarios,' addressing a clear gap in agent evaluation. While it doesn't propose a new model, the benchmark is likely to become a standard for future memory research.