📊 Experiments & Results
Evaluation Setup
Zero-shot prompting on reasoning and factuality benchmarks
Benchmarks:
- Arithmetic (Mathematical reasoning (6-term expressions))
- GSM8K (Grade school math word problems)
- Chess Move Prediction (Strategic reasoning (predict next move from PGN))
- Biographies (Factual generation (computer scientists)) [New]
- MMLU (General knowledge (multiple choice))
- Chess Move Validity (Constraint satisfaction (legal moves))
Metrics:
- Accuracy (%)
- Stockfish Pawn Score (Chess)
- Fact Recall (Biographies)
- Statistical methodology: Standard deviation reported across runs (e.g., ±4.7)
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Reasoning tasks: Debate consistently outperforms single-agent and reflection baselines on math and strategy. | ||||
| Arithmetic | Accuracy (%) | 67.0 | 81.8 | +14.8 |
| GSM8K | Accuracy (%) | 77.0 | 85.0 | +8.0 |
| Chess Move Prediction | Pawn Score Advantage (∆PS) | 91.4 | 122.9 | +31.5 |
| Factuality tasks: Debate significantly reduces hallucinations compared to single agents. | ||||
| Biographies | Fact Accuracy (%) | 66.0 | 73.8 | +7.8 |
| MMLU | Accuracy (%) | 63.9 | 71.1 | +7.2 |
| Chess Move Validity | Validity (%) | 29.3 | 45.2 | +15.9 |
Experiment Figures
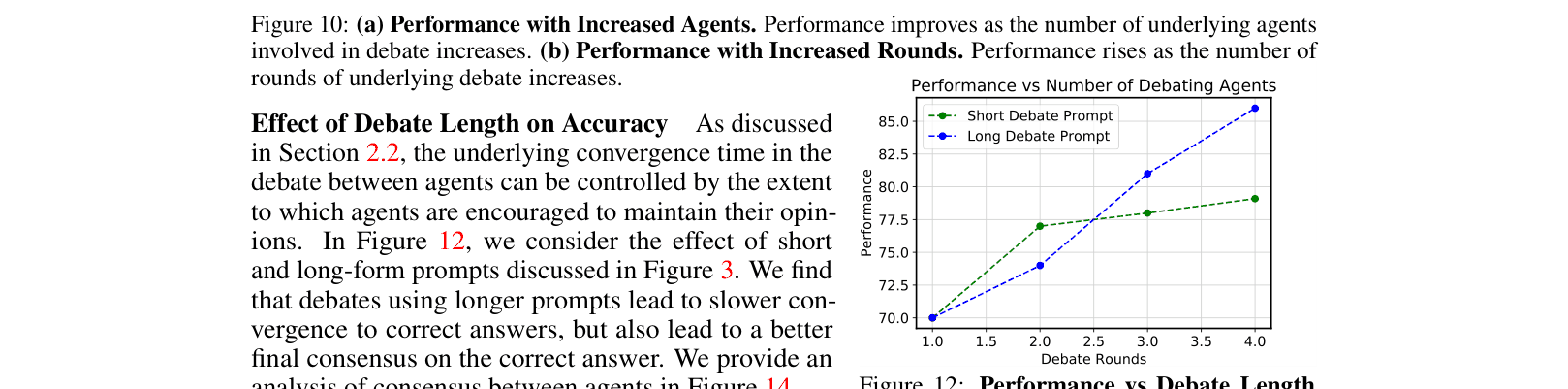
Performance trends on Arithmetic task as a function of (a) Number of Agents and (b) Debate Rounds.

Qualitative example of uncertainty in Biographies. Agents give conflicting birthplaces for a scientist (Spain vs Cuba).
Main Takeaways
- Multi-agent debate improves performance across all tested reasoning and factuality tasks, outperforming both single-agent generation and self-reflection.
- Diversity in initial responses is key; even when all agents start with incorrect answers, the debate process allows them to critique flaws and converge on a correct solution.
- Increasing the number of agents and rounds of debate generally monotonically increases accuracy, though gains diminish after ~4 rounds.
- Factuality improves because agents are 'uncertain' about hallucinations in different ways; debate filters out inconsistent facts (lies) while preserving consistent truths.
- The method is orthogonal to Chain-of-Thought; combining Debate with CoT yields even higher performance.