📝 Paper Summary
Hallucination detection
Internal state analysis
The paper introduces a lightweight, learnable steering vector added during inference to reshape LLM latent spaces, separating truthful from hallucinated representations using minimal labeled data and optimal transport.
Core Problem
Pre-trained LLM embeddings are optimized for linguistic coherence rather than factual accuracy, resulting in latent spaces where truthful and hallucinated content are not clearly separated.
Why it matters:
- Hallucinations undermine user trust and cause harm in high-stakes applications, making detection critical for safe deployment
- Existing detection methods relying on default embeddings fail because the model prioritizes fluency over truthfulness during pre-training
- Fully supervised approaches require expensive large-scale human annotations, which are impractical for many real-world applications
Concrete Example:
When an LLM generates a bio for a real person, it might mix true facts with plausible-sounding lies. Default embeddings for both truthful and hallucinated sentences look similar because both are grammatically fluent. TSV pushes these embeddings apart so a simple classifier can tell them apart.
Key Novelty
Truthfulness Separator Vector (TSV)
- Learns a single vector added to hidden states during inference that pushes truthful and hallucinated embeddings into distinct clusters without changing model weights
- Uses a two-stage training process: first clustering with a tiny labeled set, then refining with large-scale unlabeled data via optimal transport pseudo-labeling
Architecture
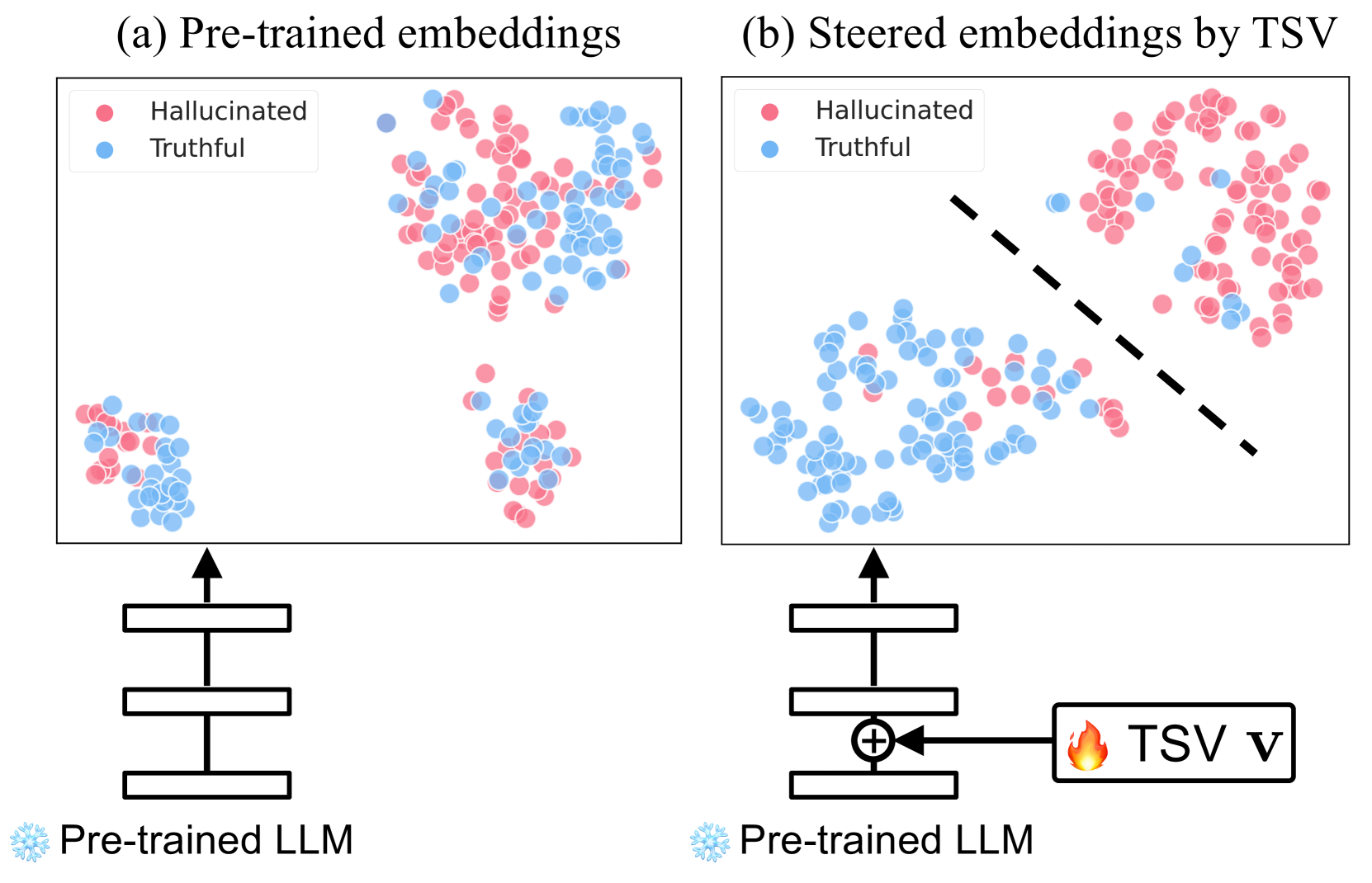
Illustration of the TSV intervention during inference and the training pipeline.
Evaluation Highlights
- +12.8% improvement in hallucination detection accuracy (AUROC) on TruthfulQA compared to state-of-the-art methods
- Achieves 84.2% AUROC on TruthfulQA with only 32 labeled examples, comparable to the fully supervised upper bound of 85.5%
- Demonstrates strong generalization to unseen datasets, maintaining competitive performance even when transferred across different domains
Breakthrough Assessment
8/10
Significant improvement in detection accuracy with minimal supervision. The approach of steering representations specifically for detection (separation) rather than generation (mitigation) is a novel and practical distinction.