📝 Paper Summary
LLM and Agentic AI Benchmarks
Multi-Agent Collaboration Protocols
Agentic RAG
AI Agent Frameworks
This survey unifies the fragmented landscape of autonomous AI agents by categorizing over 60 benchmarks, reviewing collaboration protocols, and mapping applications from scientific discovery to software engineering.
Core Problem
The rapid evolution of LLMs into autonomous agents has created a fragmented landscape of evaluation benchmarks, frameworks, and protocols that lacks a unified taxonomy.
Why it matters:
- Current benchmarks are often outdated or narrow; state-of-the-art models fail on newer reasoning tasks (e.g., <10% on Humanity's Last Exam)
- Researchers lack a consolidated view of how agent frameworks (planning, reflection) integrate with specific domain applications like healthcare or materials science
- Security vulnerabilities and collaboration failures in multi-agent systems are under-explored in existing literature
Concrete Example:
While models achieve >90% on traditional benchmarks like MMLU, they score less than 10% on the Humanity's Last Exam (HLE) benchmark, revealing a massive gap in expert-level reasoning that older metrics hide.
Key Novelty
Unified Taxonomy of Agentic AI (Benchmarks, Protocols, Applications)
- Side-by-side comparison of benchmarks from 2019 to 2025, categorized by domain (reasoning, coding, embodied, etc.)
- Review of agent-to-agent collaboration protocols including ACP, MCP, and A2A
- Detailed mapping of real-world agent applications across scientific domains (e.g., biomedical research, chemical reasoning)
Architecture
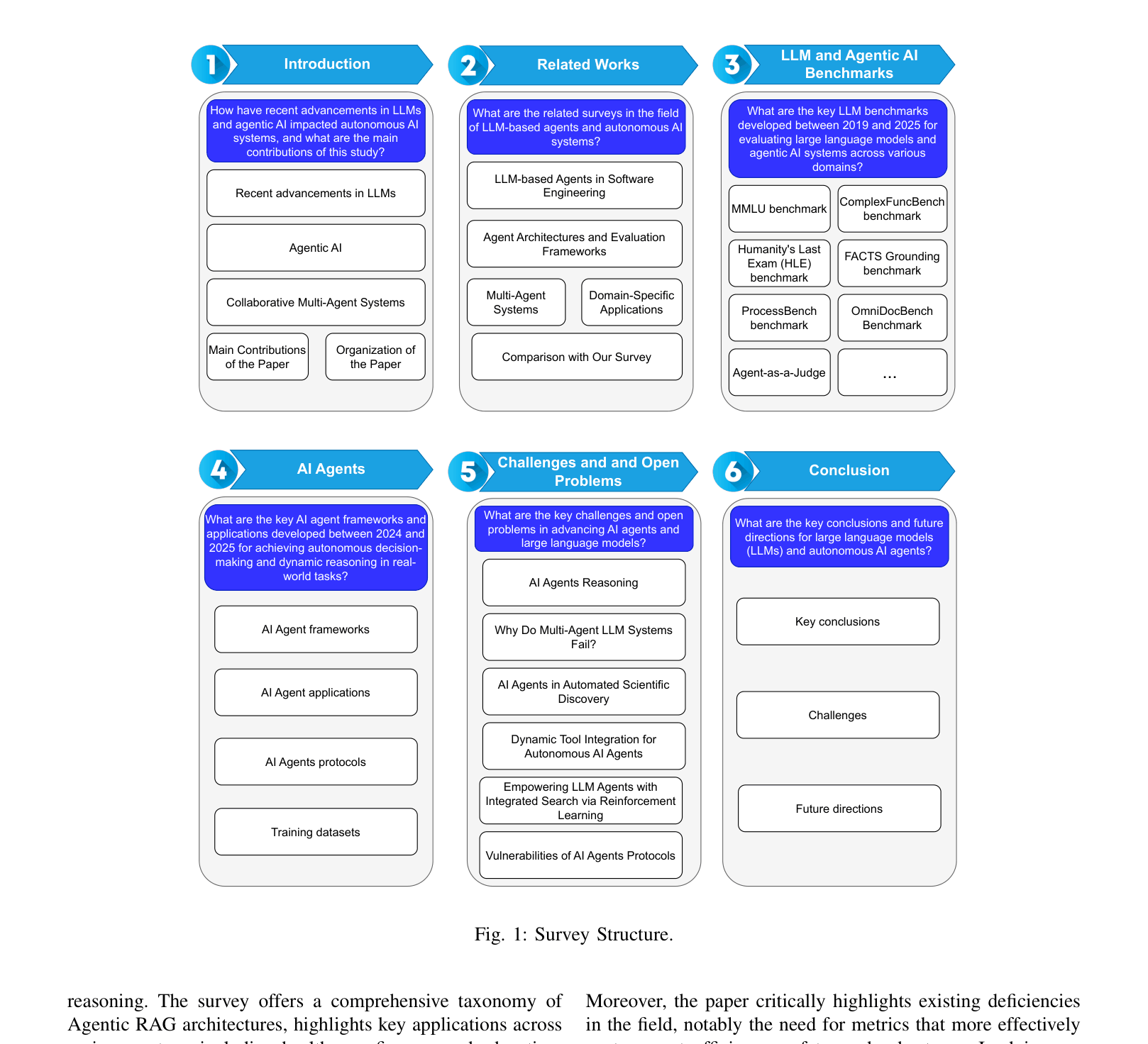
Survey Structure Diagram
Evaluation Highlights
- State-of-the-art systems achieve only ~7% accuracy on standard ENIGMAEVAL puzzles, highlighting failures in multimodal reasoning
- On Humanity's Last Exam (HLE), advanced models like DeepSeek-R1 and Claude 3.5 Sonnet score below 10%, showing significant calibration errors
- Agent-as-a-Judge framework reduces evaluation costs to ~2.29% of human costs while achieving 90% alignment with human judgments
Breakthrough Assessment
7/10
A comprehensive and timely survey that organizes a chaotic field. While it doesn't propose a new model, its taxonomy and consolidation of 2024-2025 benchmarks provide a critical roadmap for researchers.