📝 Paper Summary
Multi-agent
Agentic RAG pipeline
LLMs can perform complex cognitive work, such as deriving new physics results or detecting hallucinations, by simulating teams of expert personae within guided scenarios.
Core Problem
Standard LLM prompting often yields generic or hallucinated responses, failing to tap into the specialized behavioral patterns and latent expert knowledge encoded within the model's training corpus.
Why it matters:
- LLMs contain vast amounts of latent knowledge that simple prompts fail to elicit effectively
- Hallucinations (confabulations) in generative AI limit the utility of models for rigorous real-world tasks
- Simulating expert behaviors offers a scalable way to solve complex problems without needing access to external tools or further training
Concrete Example:
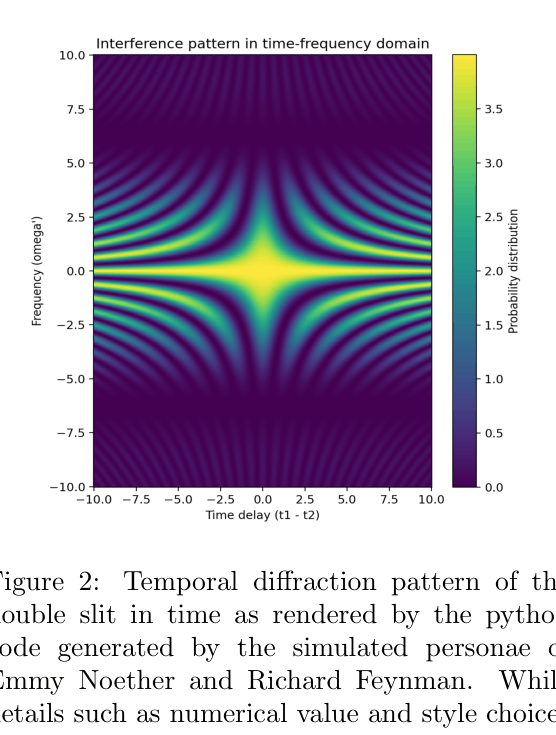
When asked simply about 'double slit time diffraction,' ChatGPT provides a vague, low-quality explanation. However, when prompted to simulate a dialogue between Richard Feynman and Emmy Noether discussing the topic with a whiteboard, it derives the correct mathematical solution.
Key Novelty
Guided Scenarios with Simulated Expert Personae
- Uses 'stage directions' and role-play prompts to condition the LLM to adopt specific expert behaviors (e.g., physicists at a whiteboard, detectives analyzing evidence)
- Leverages the dialogic structure of the training corpus to create a self-sustaining train of thought, where simulated experts correct and guide each other toward a solution
Architecture

Comparison between a simple prompt and the guided scenario strategy for the physics problem
Evaluation Highlights
- Reproduced the mathematical derivation and visualization of 'double-slit time diffraction' (a 2022 physics result outside the training horizon) using simulated Richard Feynman and Emmy Noether personae
- Achieved >90% success rate in detecting hallucinations (confabulations) regarding the JPL VITAL Ventilator project using simulated Sherlock Holmes and Dr. Watson personae
- Generated valid Python code to visualize complex interference patterns that matched peer-reviewed literature qualitatively
Breakthrough Assessment
7/10
Demonstrates a powerful, zero-shot prompting strategy that unlocks significant reasoning capabilities. While not an architectural change, the qualitative results on scientific discovery and hallucination detection are impressive.