📝 Paper Summary
Fact Verification
Hallucination detection
FactLens improves fact-checking by decomposing complex claims into atomic sub-claims and evaluating them with new metrics like atomicity and sufficiency to pinpoint nuanced errors.
Core Problem
Traditional fact-verification models assign a single holistic label to complex claims, often obscuring nuanced errors or inaccuracies buried within multi-part statements.
Why it matters:
- Holistic labels fail to identify exactly which part of a complex claim is incorrect, reducing interpretability
- Existing benchmarks lack fine-grained labels, making it difficult to evaluate the precise failure modes of LLMs
- Poorly constructed sub-claims (e.g., losing context or fabricating details) can degrade verification performance rather than help it
Concrete Example:
For the claim 'Amanda Bauer attended the University of Cincinnati. The school’s nickname is Bearcats,' a poor decomposition might output 'The school’s nickname is Bearcats.' This sub-claim lacks sufficiency because the reference to 'University of Cincinnati' is lost, making it ambiguous for verification.
Key Novelty
FactLens: A Fine-Grained Verification Benchmark & Evaluator
- Decomposes complex claims into atomic sub-claims to isolate factual errors, rather than verifying the whole sentence at once
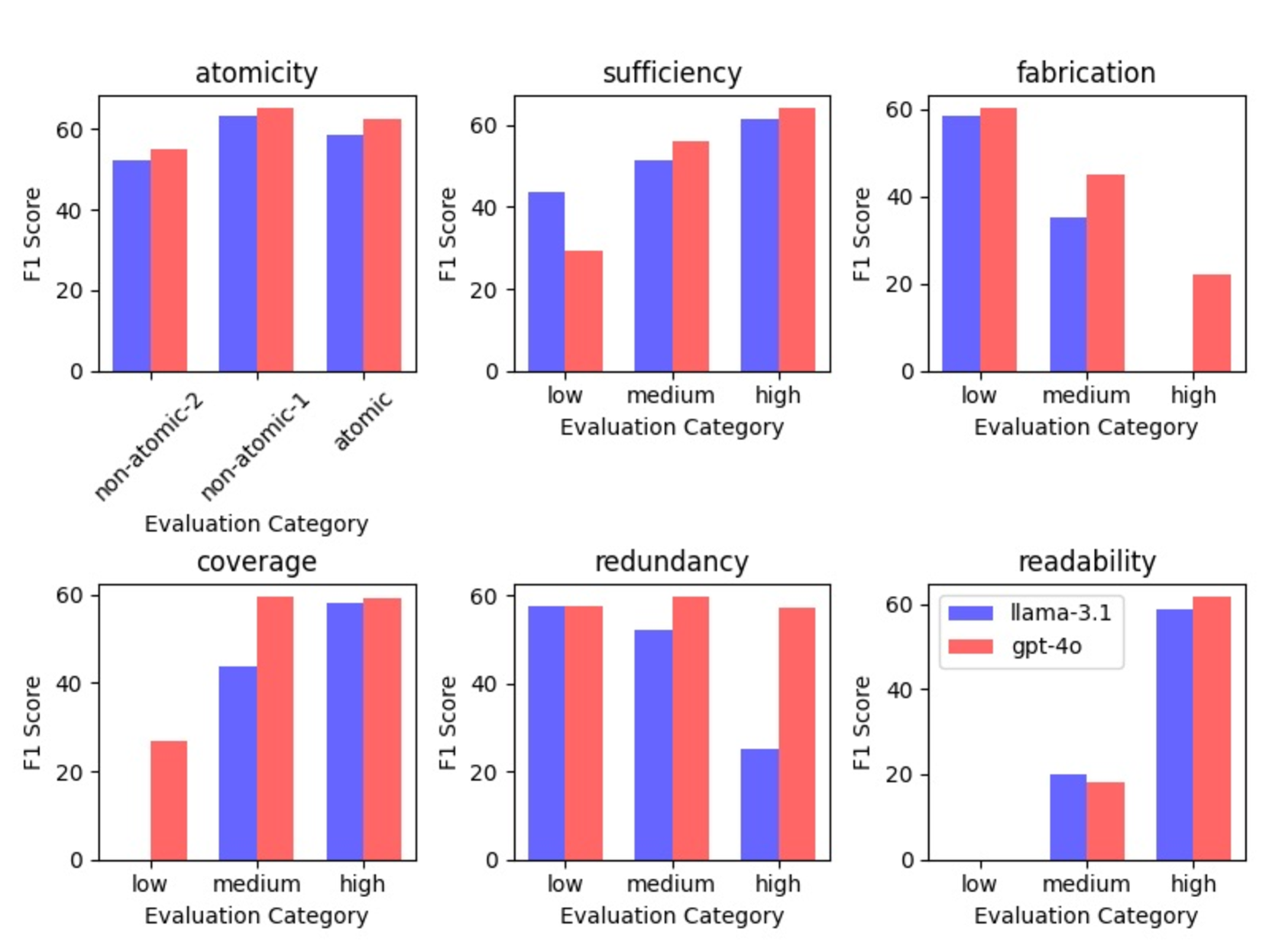
- Introduces specific quality metrics (Atomicity, Sufficiency, Fabrication, Coverage) to judge whether a sub-claim is well-formed before verification
- Provides a manually curated dataset of 733 instances with ground-truth sub-claims to benchmark decomposition models
Architecture
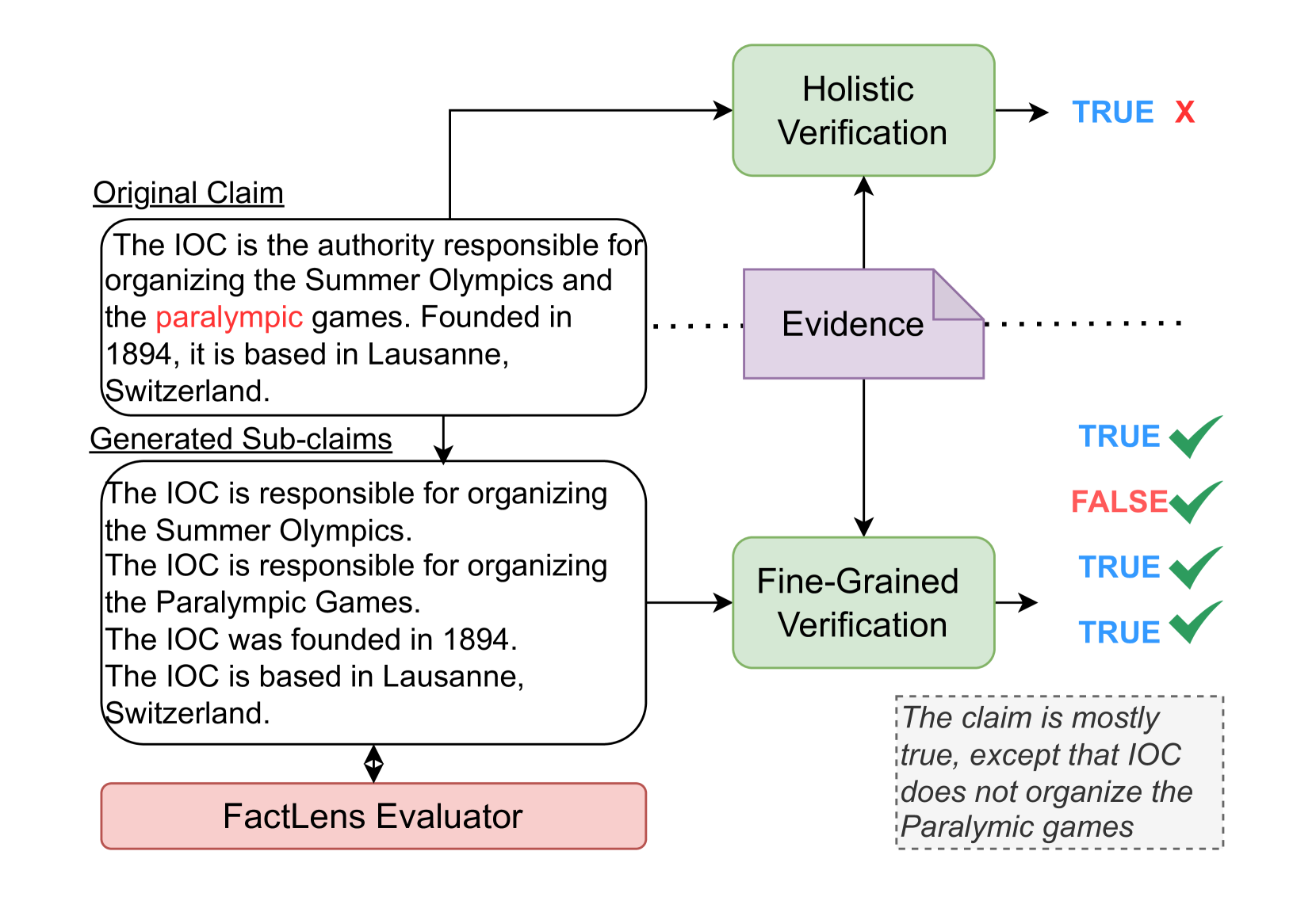
Conceptual comparison between Holistic Verification and Fine-Grained Verification pipelines
Evaluation Highlights
- FactLens automated evaluators achieve fair-to-moderate correlation with human judgments across quality dimensions like Atomicity and Coverage
- End-to-end analysis shows that sub-claims with 'low' fabrication scores lead to higher downstream F1 verification scores compared to 'high' fabrication ones
- Current SOTA models (GPT-4o, LLaMA-3.1) struggle with Atomicity, often failing to split claims with one subject and multiple objects
Breakthrough Assessment
7/10
Important step towards more granular and explainable fact-checking. The metrics and dataset are valuable contributions, though the reliance on LLMs for evaluation (despite calibration) is a known limitation.