📝 Paper Summary
Hallucination suppression
Granular uncertainty estimation
Uncertainty-aware decoding
Graph Uncertainty constructs a bipartite graph mapping generated responses to individual claims and uses graph centrality metrics like closeness centrality to estimate the factual reliability of each claim.
Core Problem
Existing uncertainty estimation methods for LLMs often operate at the response level rather than the claim level, or rely on simple frequency counting (self-consistency) that ignores complex semantic relationships.
Why it matters:
- LLMs frequently generate long-form text containing a mix of true and false claims, requiring granular detection rather than a binary correct/incorrect label for the whole text
- Current methods like self-consistency do not fully leverage the structural entailment relationships between different responses and claims, missing signals that could improve reliability
- Users cannot trust long-form generations without knowing which specific parts are hallucinations, hindering deployment in high-stakes applications
Concrete Example:
If an LLM generates a paragraph about a politician, it might correctly state their birth year but hallucinate their election date. A simple frequency count might miss that the election date claim is only supported by a few outlier responses that contradict the majority of semantic evidence, whereas a graph-based view would isolate it.
Key Novelty
Graph-based Uncertainty Estimation with Centrality Metrics
- Constructs a bipartite graph where one set of nodes represents generated responses and the other represents extracted claims, with edges representing entailment
- Generalizes the popular 'self-consistency' method (which uses degree centrality) by applying more sophisticated graph metrics like closeness centrality to determine claim reliability
- Uses these granular uncertainty scores to filter out unreliable claims during decoding, synthesizing a final response that preserves high-confidence information
Architecture
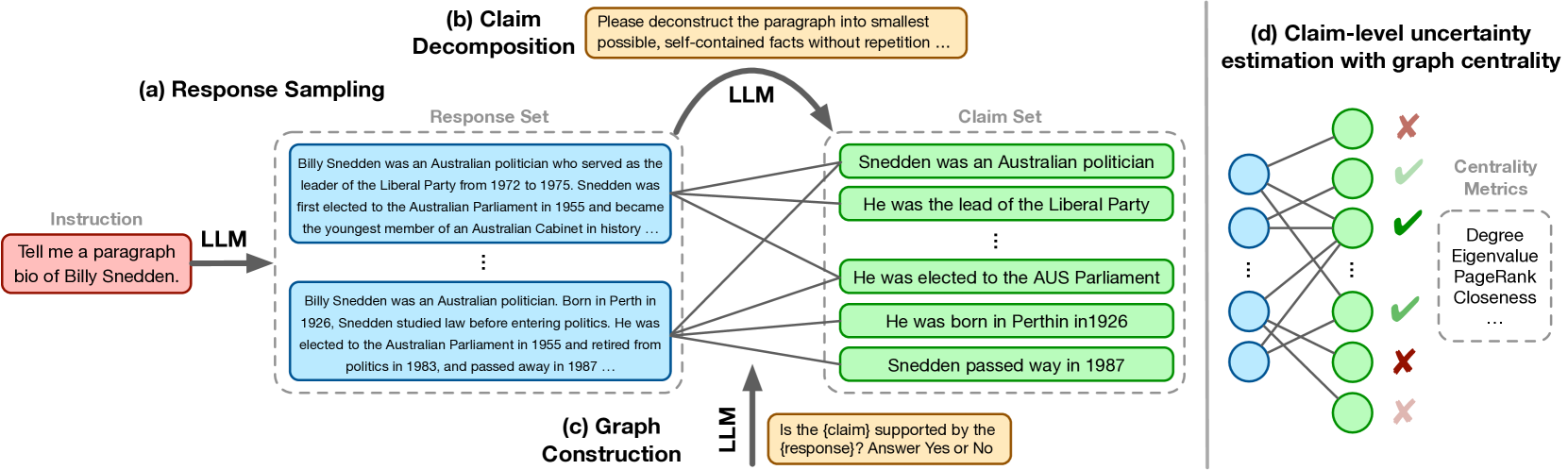
Illustration of the Graph Uncertainty framework. It shows the process from Response Sampling -> Claim Decomposition -> Bipartite Graph Construction -> Centrality Calculation.
Evaluation Highlights
- Outperforms baselines by an average of 6.8% on AUPRC (Area Under Precision-Recall Curve) for claim-level uncertainty estimation on FactScore and PopQA datasets
- Achieves consistent 2-4% gains in factuality (FactScore) over existing decoding techniques while maintaining informativeness
- Generates 70% more true claims at the 95% precision level compared to baseline methods like Self-Consistency and Verbalized Confidence
Breakthrough Assessment
8/10
Significantly generalizes the dominant self-consistency paradigm into a graph framework. The empirical gains on granular claim-level detection are substantial, addressing a critical bottleneck in long-form generation.