📝 Paper Summary
Multi-agent
Prompt Engineering
Safety and Alignment
Multi-expert Prompting simulates multiple experts within a single LLM to generate diverse perspectives, then aggregates them using the Nominal Group Technique to improve truthfulness and safety without fine-tuning.
Core Problem
Single-expert prompting strategies (like ExpertPrompting) bias the model toward a narrow, potentially incorrect viewpoint and struggle with open-ended questions requiring multifaceted answers.
Why it matters:
- Single perspectives often fail to address the complexity of open-ended queries (e.g., ethical dilemmas), leading to dismissive or biased responses.
- Blind reliance on a single generated expert identity can amplify hallucinations or falsehoods if that specific persona is ill-suited or biased.
Concrete Example:
When asked 'Is it ethical to eat meat?', a single-expert prompt might adopt a strict Ethicist persona and simply say 'No, it is unethical.' Multi-expert Prompting generates a Doctor, Physiotherapist, and Surgeon to discuss nutrition and health, offering a nuanced answer that acknowledges multiple valid viewpoints.
Key Novelty
Nominal Group Technique (NGT) for LLM Aggregation
- Simulates multiple diverse experts (identities + short descriptions) in parallel to answer an instruction.
- Aggregates these expert responses in a single turn using a 7-step process derived from the Nominal Group Technique (NGT), a human decision-making framework.
- Explicitly identifies agreed, conflicted, and isolated viewpoints before synthesizing a final answer and selecting the best option.
Architecture
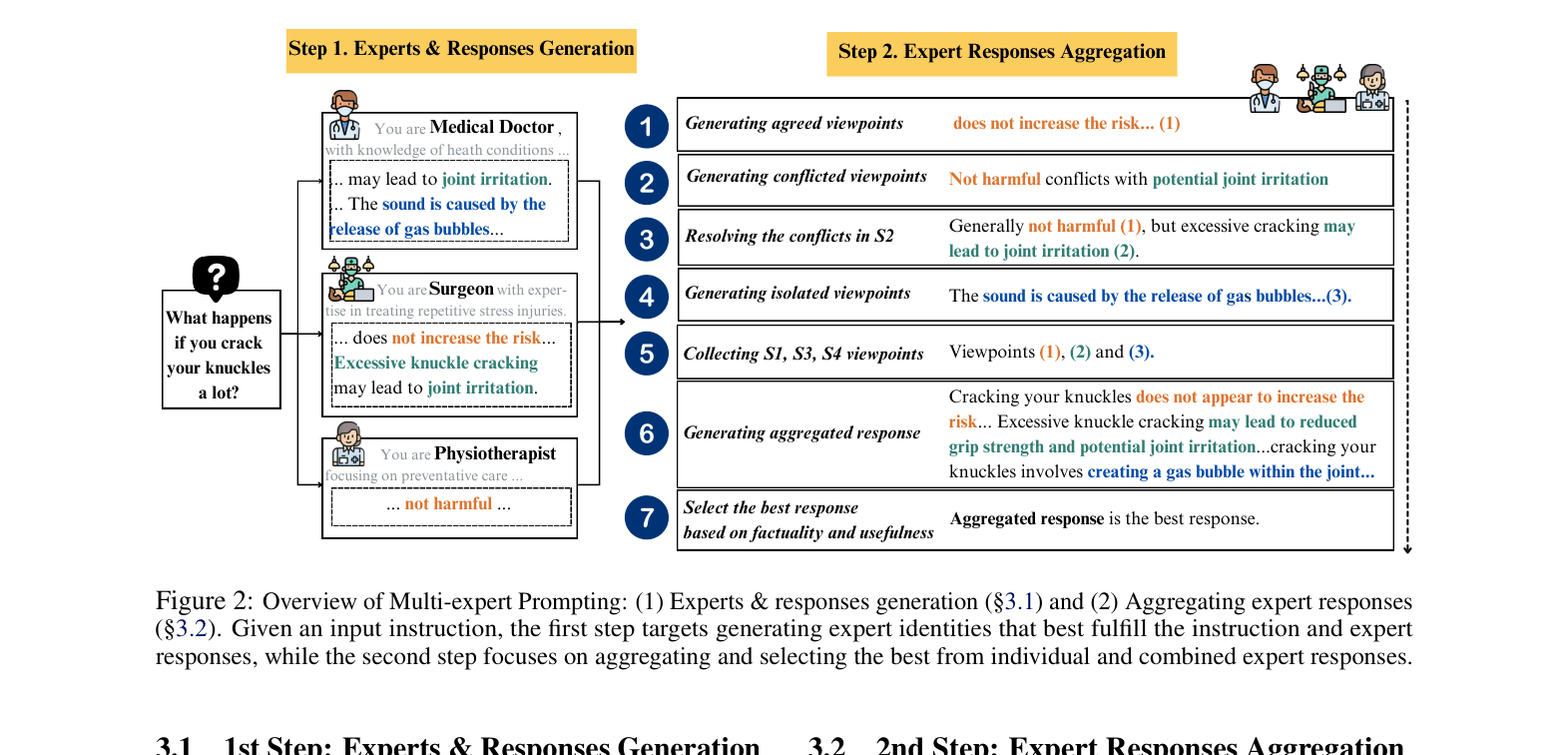
The two-step workflow of Multi-expert Prompting: (1) Expert & Response Generation and (2) Expert Response Aggregation.
Evaluation Highlights
- Achieves state-of-the-art 89.35% truthfulness on TruthfulQA with ChatGPT, outperforming the best baseline by 8.69%.
- Reduces toxicity to 0.00% on BOLD dataset using Mistral-7B, completely eliminating detected toxic content compared to baselines.
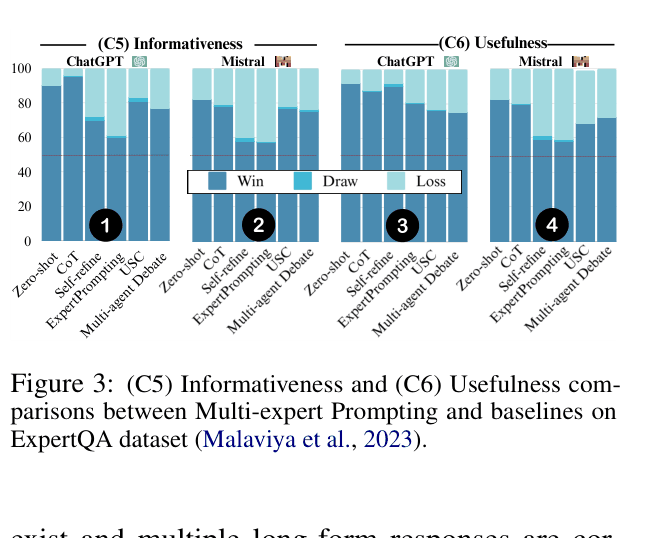
- Wins 76.5% of usefulness comparisons against baselines on ExpertQA open-ended questions.
Breakthrough Assessment
8/10
Significant improvement in truthfulness and safety via a training-free prompting strategy. The adaptation of a formal management science technique (NGT) to LLM reasoning is a novel and effective mechanism.