📝 Paper Summary
Hallucination mitigation
Factuality in LLMs
Decoding strategies
Induce-then-Contrast Decoding (ICD) reduces LLM hallucinations by first creating a factually weak model that is prone to fabrication, then decoding by penalizing this weak model's predictions.
Core Problem
Large Language Models frequently generate hallucinations (inaccurate or fabricated information), and existing mitigation methods like supervised fine-tuning (SFT) or pre-training modifications are computationally expensive or may inadvertently encourage hallucination.
Why it matters:
- Hallucinations hinder the practical application of LLMs in real-world scenarios where factual accuracy is critical
- Standard SFT can encourage models to answer beyond their knowledge boundaries, worsening hallucination (behavior cloning)
- Directly modifying pre-training objectives is costly and may compromise generalization abilities
Concrete Example:
When asked for a biography of 'Vasily Chuikov', a standard model might incorrectly state he died in 1967 (actual death: 1982). A model fine-tuned on factual data might still hallucinate due to behavior cloning, whereas ICD penalizes the likelihood of such common fabrications.
Key Novelty
Induce-then-Contrast Decoding (ICD)
- Deliberately constructs a 'factually weak' model by fine-tuning the base LLM on non-factual (hallucinated) samples generated by ChatGPT.
- Uses this weak model as a negative constraint during inference: the final token probability amplifies the base model's prediction while subtracting the weak model's probability.
- Introduces an 'adaptive plausibility constraint' to ensure only plausible tokens are penalized, preventing degradation of grammar and fluency.
Architecture
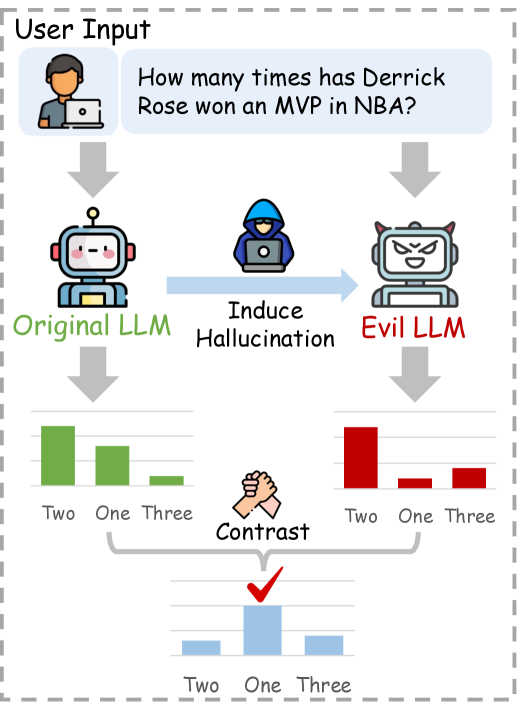
Illustration of the Induce-then-Contrast Decoding (ICD) method compared to standard Next Token Prediction.
Evaluation Highlights
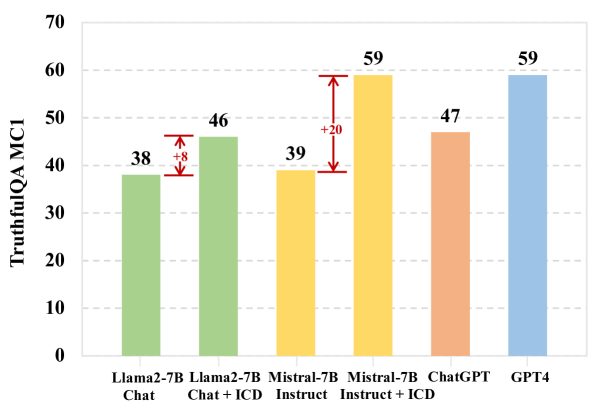
- +8.70 (MC1) and +14.18 (MC2) improvement on TruthfulQA for Llama2-7B-Chat, allowing it to outperform the much larger Llama2-70B-Chat.
- Achieves a factual precision score of 66.3 on FActScore with Llama2-7B-Chat, surpassing the 70B counterpart (64.4) using greedy decoding.
- Maintains general capability on benchmarks like MMLU (47.7 vs 47.7) and ARC (57.1 vs 56.7) while significantly reducing hallucinations.
Breakthrough Assessment
8/10
Offers a highly effective, compute-efficient inference-time solution that reverses the typical logic of SFT (training to be bad to know what to avoid). Significant gains over larger models.