📝 Paper Summary
Hallucination suppression
Reasoning elicitation
CoK prompting mitigates hallucinations by urging LLMs to generate structured knowledge triples as evidence, verified for factuality and faithfulness to trigger rethinking if unreliable.
Core Problem
Standard Chain-of-Thought (CoT) prompting often leads to hallucinations where generated rationales are unfactual or unfaithful, causing wrong answers despite seemingly logical steps.
Why it matters:
- LLMs generate plausible but fake reasoning steps (e.g., wrong player profession), leading to incorrect conclusions.
- Faithfulness gaps occur when reasoning chains are logically sound but do not actually support the final answer derived by the model.
Concrete Example:
Query: 'Is the following sentence plausible: Derrick White backhanded a shot.' Standard CoT fails by hallucinating 'Derrick White is most likely a hockey player' (unfactual). CoK retrieves the triple (Derrick White, is a, Basketball player), correcting the reasoning to 'False'.
Key Novelty
Chain-of-Knowledge (CoK) Prompting with F2-Verification
- Replaces vague textual rationales with 'Evidence Triples' (structured subject-relation-object data) combined with explanation hints, mimicking a human mind map.
- Introduces F2-Verification to calculate scores for both Factuality (match with Knowledge Base) and Faithfulness (consistency between rationale and answer).
- Implements a 'Rethinking' loop: if the reliability score is below a threshold, the system injects correct knowledge triples and prompts the LLM to generate the answer again.
Architecture
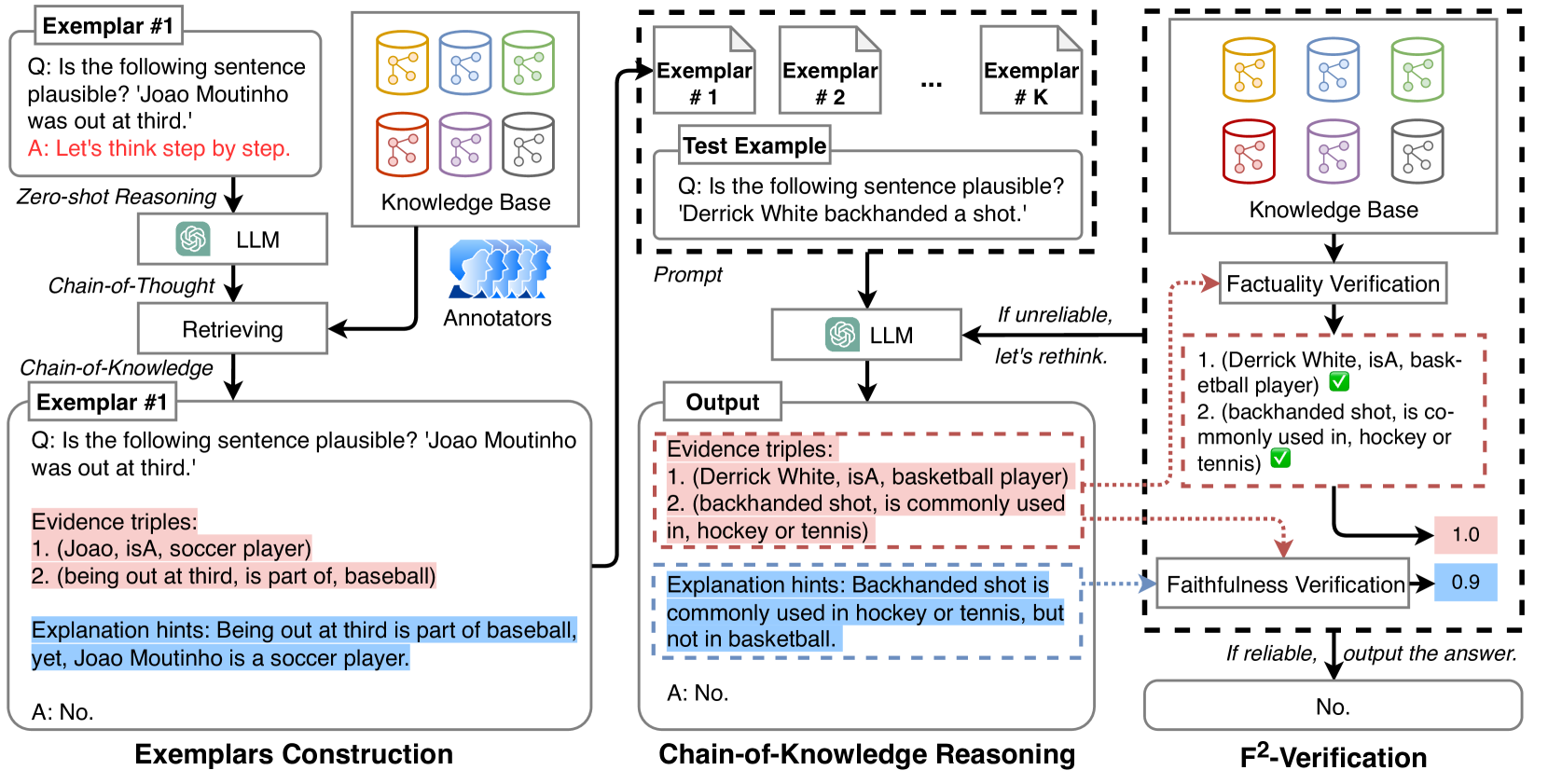
The overall framework of CoK, including Exemplar Construction and the Inference process with F2-Verification and Rethinking.
Evaluation Highlights
- +9.4% improvement on CommonsenseQA compared to standard Chain-of-Thought (CoT) prompting.
- Outperforms Auto-CoT by +6.1% on the StrategyQA benchmark.
- Achieves higher performance than self-consistency methods on arithmetic reasoning tasks like GSM8K.
Breakthrough Assessment
7/10
Novel integration of structured knowledge triples into the prompting sequence itself, combined with a dynamic verification and rethinking loop. Strong empirical gains on reasoning tasks.