📝 Paper Summary
Hallucination detection
Fact verification
FactCG improves hallucination detection by training small classifiers on synthetic data generated from document context graphs, forcing models to learn multi-hop reasoning rather than simple sentence matching.
Core Problem
Existing synthetic training data for factuality classifiers lacks the complexity of real LLM hallucinations, which often require multi-hop reasoning across a document.
Why it matters:
- LLM-based judges are too expensive and slow for real-time applications
- Current small classifiers trained on NLI or simple synthetic data fail to detect complex hallucinations where reasoning spans multiple sentences
- Real LLM hallucinations contain 2-4 reasoning hops, whereas previous synthetic datasets (like MiniCheck's D2C) mostly contain single-hop claims
Concrete Example:
A real LLM might hallucinate a connection between two entities mentioned in different paragraphs (e.g., 'X is the director of Y') based on a document where the link is only implied via a third entity. Simple synthetic generators often just swap entities in a single sentence, failing to teach the classifier this multi-step verification.
Key Novelty
Context Graph to Claim (CG2C) Data Generation
- Extracts a knowledge graph from a document and identifies connected sub-graphs (chains of entities and relations)
- Generates synthetic claims based on these sub-graphs to ensure they require multi-hop reasoning to verify
- Creates negative samples by programmatically removing specific relations from the document while keeping the claim, forcing the model to detect the missing link
Architecture
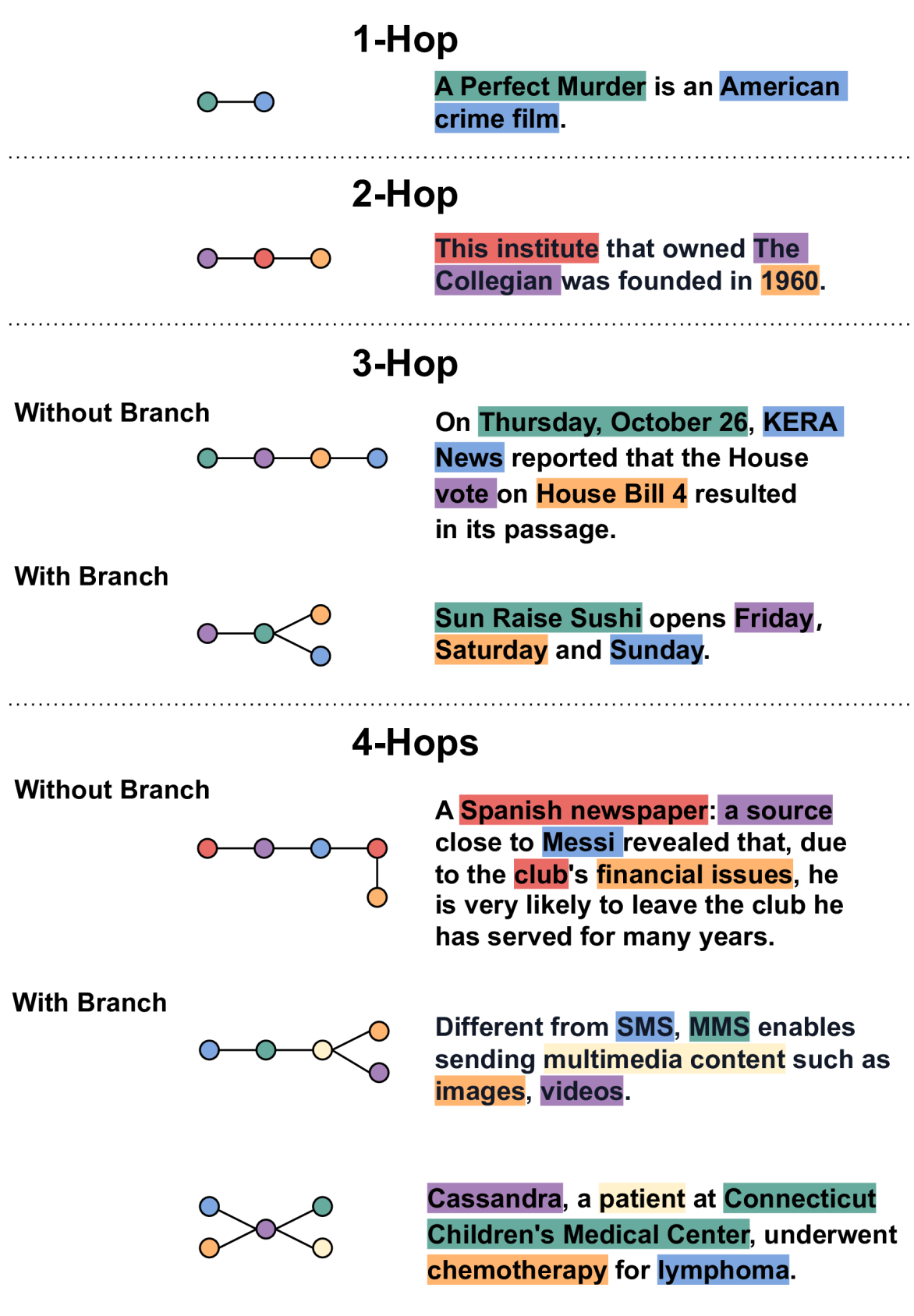
The Context Graph to Claim (CG2C) data generation process.
Evaluation Highlights
- Outperforms GPT-4-o on the LLM-AGGREFACT benchmark by +1.1 points in balanced accuracy using a much smaller model (FactCG-DeBERTa)
- Achieves state-of-the-art performance among comparable small models, beating MiniCheck-DeBERTa by +1.2 points on LLM-AGGREFACT
- Demonstrates better connected reasoning: performance drops less than baselines when supporting sentences are shuffled, indicating less reliance on disconnected shortcuts
Breakthrough Assessment
8/10
Significantly closes the gap between open-source classifiers and GPT-4 for fact-checking by addressing the specific structural deficit (multi-hop reasoning) in synthetic training data.