📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Image Captioning
Hallucination Mitigation
CapMAS improves detailed image captions by using an LLM to decompose long descriptions into atomic claims, which an MLLM then verifies against the image to remove hallucinations.
Core Problem
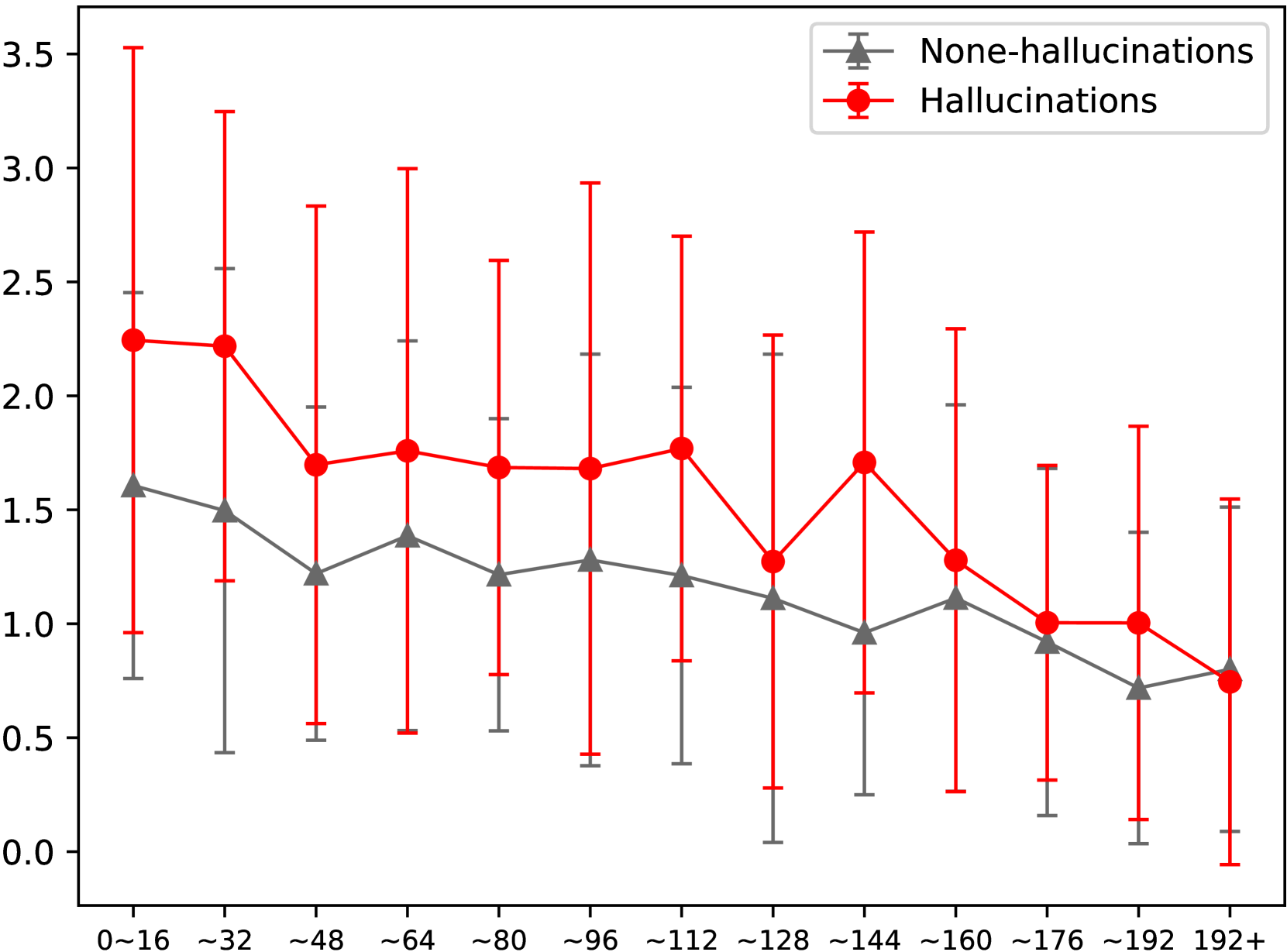
Existing MLLMs hallucinate frequently when generating long, detailed captions because they rely more on their own generated text than the input image as sequence length increases.
Why it matters:
- Current hallucination detection methods (Confidence, Consistency) fail to detect errors that occur later in long sequences (after ~192 tokens)
- Standard captioning metrics (BLEU, CIDEr) require reference captions, which are impractical to collect for hyper-detailed descriptions
- High-stakes applications like visual assistance for the impaired require descriptions that are both exhaustive (high coverage) and strictly factual
Concrete Example:
In a long caption, an MLLM might correctly describe a room but then hallucinate 'a small red ball' at the very end. Standard methods checking token probabilities won't catch this because the model is confident in its own language flow, even though the ball isn't in the image.
Key Novelty
Caption factuality enhancing MultiAgent System (CapMAS)
- Decomposition-Verification-Revision: Instead of correcting the whole text at once, an LLM breaks the caption into tiny 'True/False' statements (atomic propositions).
- Context Isolation: An MLLM verifies each statement independently against the image, breaking the 'language prior' bias that causes hallucinations in long sequences.
- Evaluation Framework: Introduces a new dual-metric approach measuring both 'Factuality' (using GPT-4o verification) and 'Coverage' (using a custom VQA dataset).
Architecture
The CapMAS pipeline: Decomposition, Verification, and Revision.
Evaluation Highlights
- Significantly outperforms baselines in detecting hallucinations; the 'Isolation' method achieves much higher AUROC than confidence-based or consistency-based methods on long captions
- Proposed evaluation metric aligns better with human judgment than existing metrics like CLAIR or ALOHa when testing against synthetic hallucination datasets (Object, Attribution, Relation)
- Improves the factuality of captions generated by state-of-the-art models, including GPT-4V, without requiring any model training (plug-and-play)
Breakthrough Assessment
8/10
Identifies a critical failure mode in current hallucination detection (length bias) and proposes a robust, training-free multi-agent solution. The new evaluation framework for detailed captions is also a significant contribution.