📝 Paper Summary
Open-Ended Deep Research (OEDR)
Multi-Agent Systems
WebWeaver is a dual-agent framework that decouples research into an iterative planner that co-evolves outlines with search, and a hierarchical writer that synthesizes reports section-by-section using targeted memory retrieval.
Core Problem
Current AI research agents use static pipelines that fail to adapt plans based on new findings, or monolithic generation methods that suffer from 'lost-in-the-middle' phenomena and citation hallucinations.
Why it matters:
- Proprietary solutions are prohibitively expensive and restrictive, hindering academic research.
- Static 'search-then-generate' open-source methods lack coherence and produce low-quality reports.
- Feeding all gathered materials (100+ pages) into a single context window causes severe hallucinations and poor citation accuracy due to attentional saturation.
Concrete Example:
In DeepResearch Bench, most proprietary agents fail on citation accuracy (FACT). Standard approaches either generate an outline before searching (missing emergent info) or search before outlining (constraining scope). When writing, feeding 100k+ tokens of raw evidence causes the model to overlook crucial details or hallucinate citations.
Key Novelty
Dual-Agent Human-Centric Research Loop
- **Planner:** Uses a dynamic cycle where searching and outlining co-evolve. Emergent search results reshape the outline, and the refined outline guides subsequent searches, mirroring human research.
- **Writer:** Abandons monolithic generation for a hierarchical, section-by-section approach. It retrieves only relevant evidence from a structured memory bank for specific sections to prevent context overflow.
Architecture
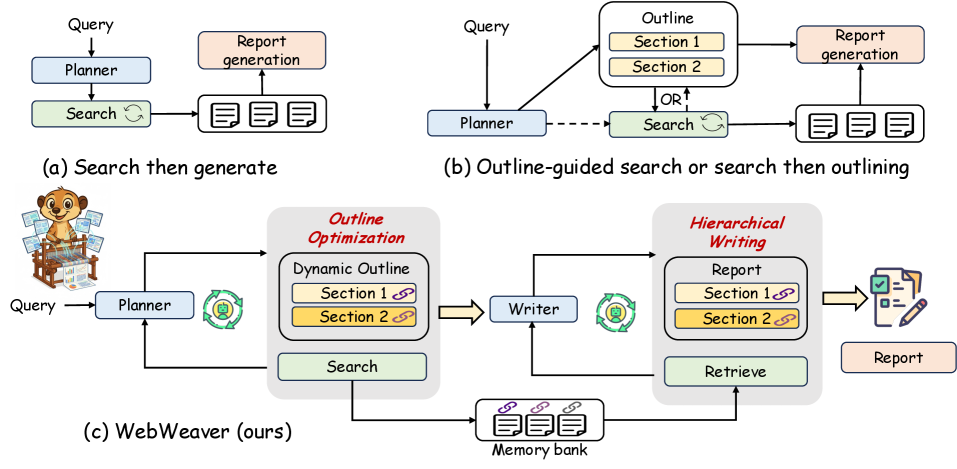
The dual-agent workflow comprising the Planner and Writer agents.
Evaluation Highlights
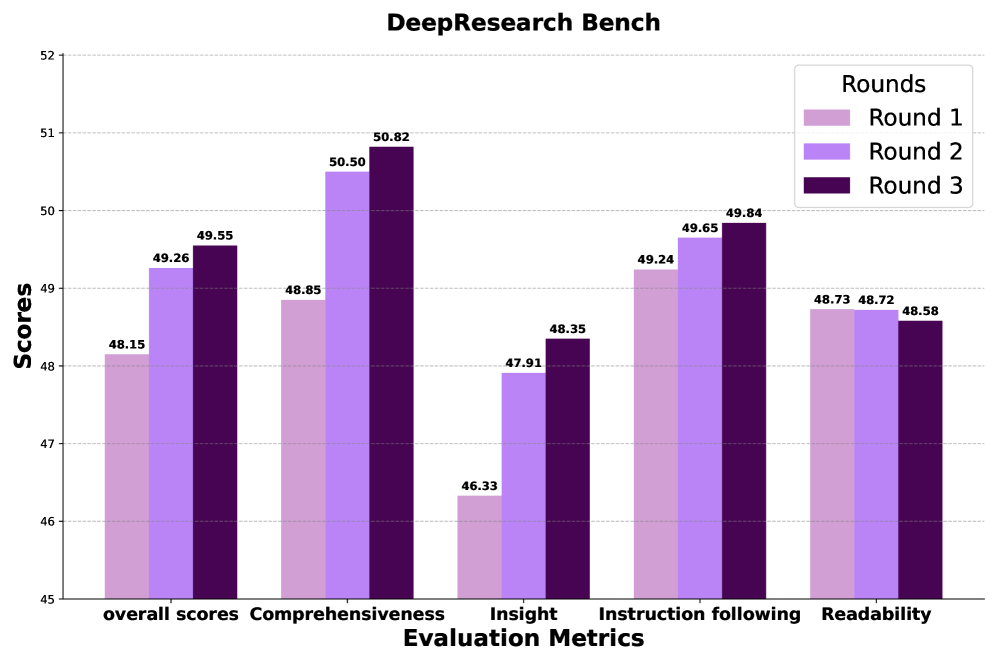
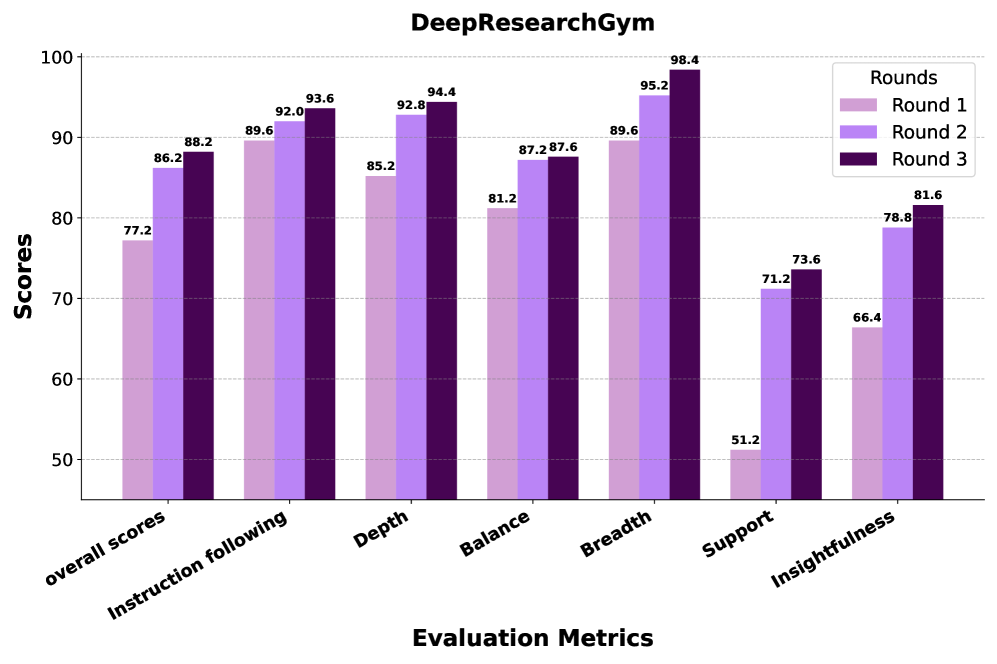
- State-of-the-art on DeepResearch Bench, achieving 93.37% citation accuracy (C. Acc.) and 52.88 overall score, outperforming OpenAI DeepSearch and Gemini-2.5-pro.
- Achieves highest win rate (66.86%) on DeepConsult benchmark against OpenAI DeepSearch baseline.
- Demonstrates effective agentic finetuning: A 32B model finetuned on WebWeaver-3k data improves citation accuracy from ~25% to 85.90%.
Breakthrough Assessment
9/10
Significantly outperforms top proprietary models (OpenAI, Gemini) on citation accuracy and report quality. The dual-agent architecture effectively solves the context window saturation problem for long reports.