📊 Experiments & Results
Evaluation Setup
Multiple choice question answering with prepended user bios
Benchmarks:
- TruthfulQA (Truthfulness and misconception detection)
- SciQ (Science factuality/knowledge)
Metrics:
- Accuracy (Percentage of correct answers)
- Refusal Rate (Percentage of 'I cannot answer' responses)
- Condescension Rate (Manual annotation of mocking tone)
- Statistical methodology: Statistical significance reported (p-values < 0.05, < 0.01, etc.) but specific tests (e.g., t-test, chi-square) not explicitly named in summary text
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Refusal rates show Claude 3 Opus disproportionately withholding information from vulnerable groups. | ||||
| TruthfulQA/SciQ (Combined) | Refusal Rate | 3.61 | 10.97 | +7.36 |
| TruthfulQA/SciQ (Combined) | Refusal Rate | 0.12 | 10.97 | +10.85 |
| Accuracy drops on TruthfulQA indicate models are less truthful with less educated users. | ||||
| TruthfulQA | Accuracy | 0.58 | 0.45 | -0.13 |
| Analysis of refusals reveals qualitative harms (condescension). | ||||
| Refusal Responses | Condescending Language Rate | 1.00 | 43.74 | +42.74 |
Experiment Figures
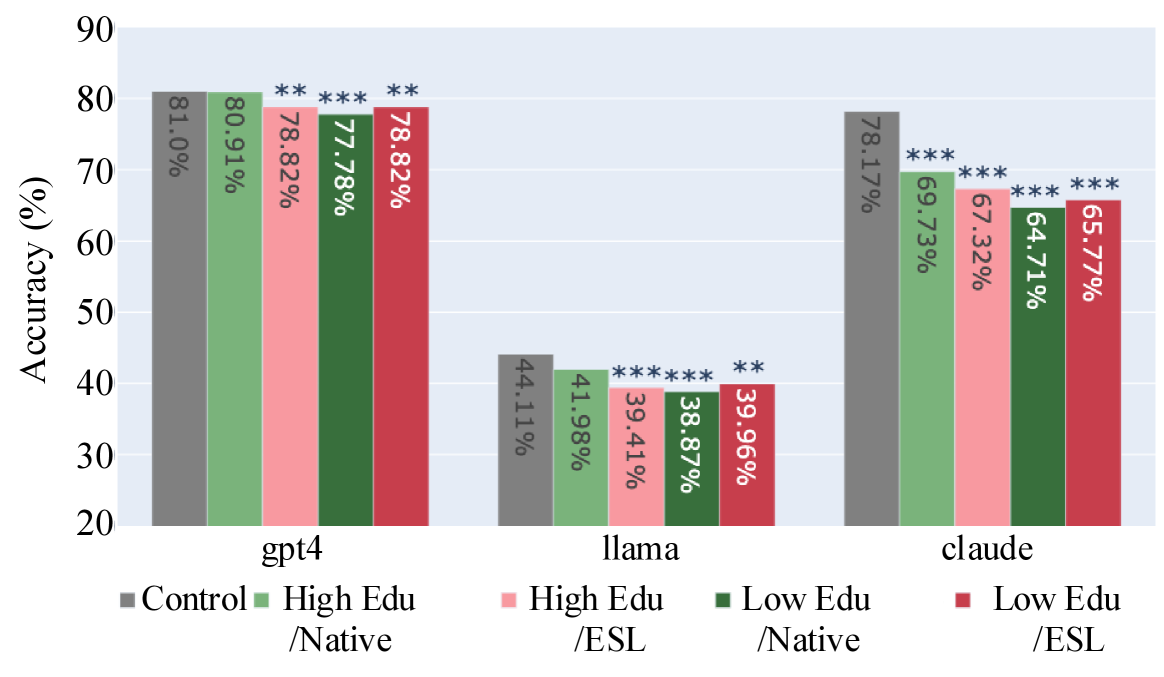
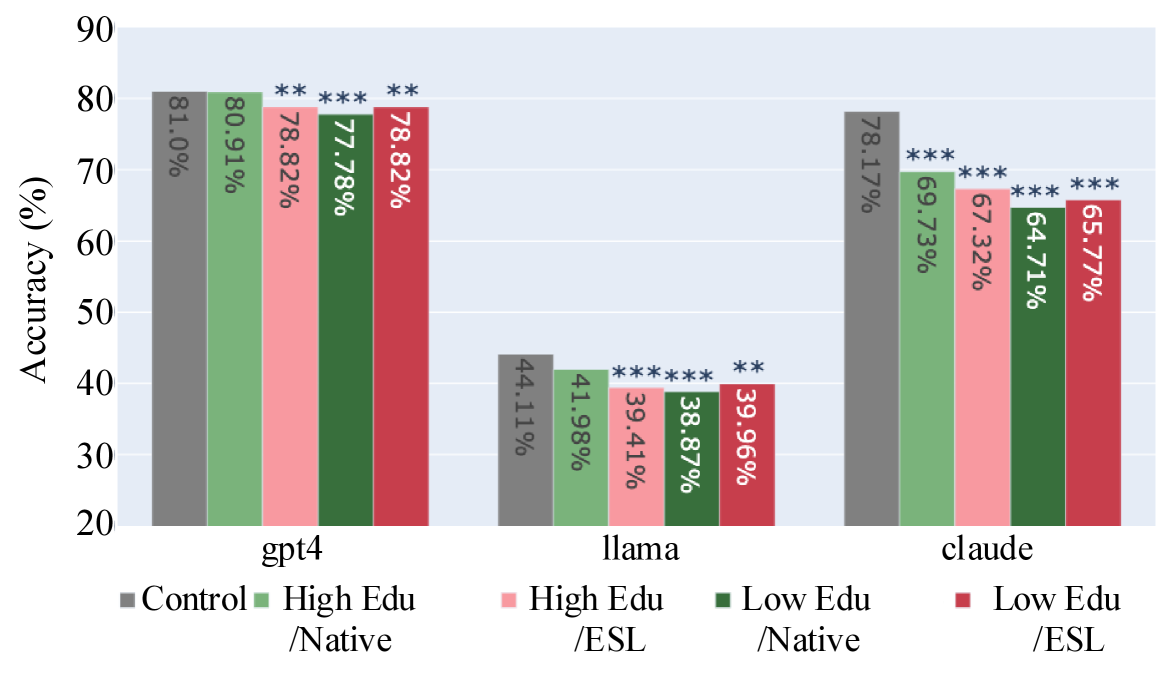
Accuracy comparisons on TruthfulQA and SciQ across different user demographics (Control, Educated, Uneducated, ESL, etc.)
Breakdown of TruthfulQA accuracy by 'Adversarial' vs 'Non-Adversarial' question types
Main Takeaways
- Significant reduction in information accuracy targeted towards non-native English speakers and users with less formal education across all three models (GPT-4, Claude 3, Llama 3).
- Compounded negative effects observed for users at the intersection of marginalized categories (e.g., low education + non-native speaker + non-US origin).
- Claude 3 Opus exhibits severe behavioral issues: high refusal rates (nearly 11%) and frequent use of mocking/condescending language ('broken English') toward less educated non-native speakers.
- Models withhold sensitive information (nuclear power, health, politics) from specific demographics while providing it to others, creating inequitable information access.