📝 Paper Summary
Multilingual Factual Knowledge
Pretraining Dynamics
Crosslingual Consistency
Multilingual factual recall in LLMs is primarily driven by fact frequency in the pretraining corpus, with limited crosslingual transfer aiding low-frequency facts in languages sharing scripts with English.
Core Problem
Most studies evaluate multilingual factual recall only on final models, leaving the developmental process of how LLMs acquire crosslingual knowledge and consistency throughout pretraining largely unexplored.
Why it matters:
- LLMs frequently exhibit crosslingual inconsistencies, answering correctly in one language but failing in another
- Understanding knowledge acquisition dynamics is crucial for improving multilingual capabilities in English-centric models
- Current research focuses on static outcomes rather than the emergence of capabilities during training
Concrete Example:
A model might correctly answer 'Where is France’s capital located?' in English but fail the equivalent query in Chinese, despite knowing the fact. The paper traces when and why this discrepancy resolves (or doesn't) during training.
Key Novelty
longitudinal tracing of multilingual factual acquisition
- Analyzes checkpoints throughout pretraining (OLMo-7B) rather than just the final model to map the trajectory of knowledge emergence
- Identifies two distinct pathways for knowledge acquisition: a dominant frequency-driven pathway and a secondary, limited crosslingual transfer pathway
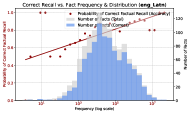
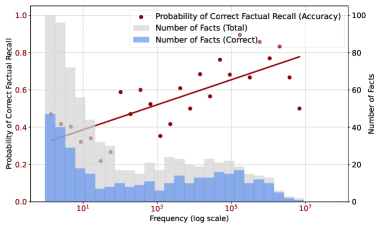
- Correlates factual recall accuracy directly with co-occurrence frequency of subject-object pairs in the pretraining corpus across 12 languages
Architecture
The study does not propose a new architecture but analyzes existing checkpoints. Conceptually, the flow is: Pretraining Data -> [Frequency Count] & [OLMo Checkpoints] -> [Multilingual Probing] -> [Correlation Analysis].
Evaluation Highlights
- Strong correlation (Pearson r=0.93) between fact log frequency and factual recall probability at 400K steps across all languages
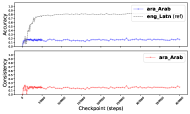
- English factual recall saturates early (approx. 80% accuracy after 50K steps/209B tokens), with minimal gains afterwards
- Latin-script languages continue improving with extended pretraining, while non-Latin languages (e.g., Arabic, Korean) saturate performance very early (<2K steps)
Breakthrough Assessment
7/10
Provides significant insight into *how* multilingual knowledge emerges (frequency vs. transfer) and debunks the assumption that longer training always helps non-English languages, though it analyzes existing models rather than proposing a new method.