📝 Paper Summary
Hallucination detection
Benchmark dataset creation
AutoHall automatically constructs model-specific hallucination datasets by prompting LLMs to generate references for known claims and then detecting contradictions between those references and ground-truth labels.
Core Problem
Existing hallucination datasets require expensive manual annotation and become obsolete quickly because hallucinations are model-specific; a claim hallucinated by Llama-2 might be answered correctly by GPT-4.
Why it matters:
- Manual annotation is laborious, expensive, and difficult to scale across the rapid release of new LLMs
- Datasets are time-sensitive; model upgrades (e.g., GPT-3.5 to GPT-4) change hallucination patterns, rendering old static benchmarks ineffective
- Different models exhibit distinct types and rates of hallucination, necessitating model-specific evaluation rather than a 'one-size-fits-all' dataset
Concrete Example:
When describing Jo Nesbø’s novel 'The Leopard', ChatGPT fabricates plot details not present in the book. A static dataset might not capture this specific error for a newer model, or might penalize a model that actually knows the book correctly.
Key Novelty
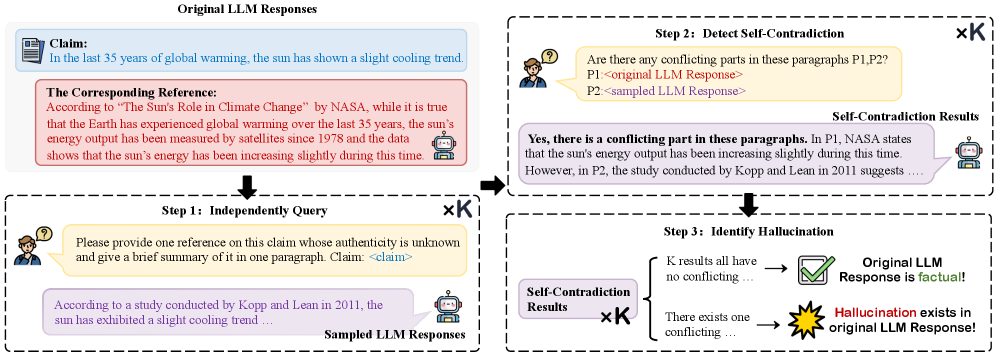
Automated Model-Specific Dataset Construction & Self-Contradiction Detection
- Leverages existing fact-checking datasets (claims + labels) to prompt LLMs to generate 'references'; if a generated reference leads to an incorrect factuality classification, it is labeled as a hallucination
- Introduces a zero-resource detection method that checks for 'self-contradiction' by comparing the original response against multiple new responses generated from functionally similar prompts
Architecture
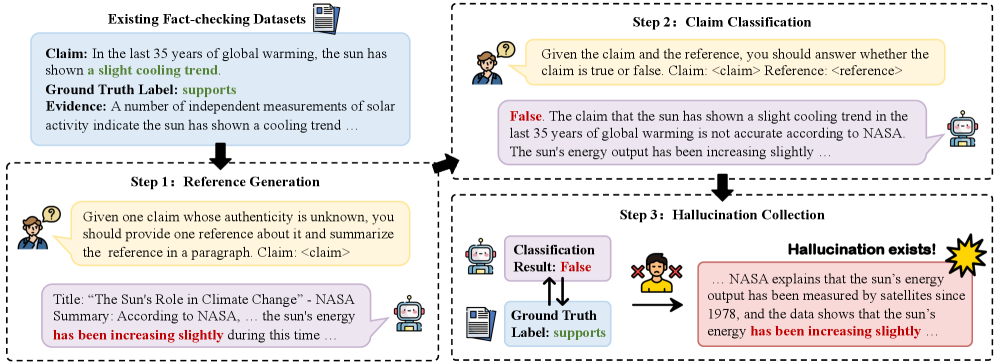
The three-step pipeline for AutoHall dataset construction.
Evaluation Highlights
- Proposed method outperforms SelfCheckGPT variants (BERTScore, NLI, Prompt) by margins ranging from +1.3% to +17% in AUC-ROC on Llama-2-70b
- Estimated prevalence of factuality hallucination in current LLMs (ChatGPT, Llama 2) is between 20% and 30%
- Demonstrates that LLMs are particularly susceptible to hallucinations in domain-specific topics like history, technology, and geography
Breakthrough Assessment
7/10
Offers a practical, scalable solution to the 'static benchmark' problem by automating dataset creation. The method is logical and effective, though primarily an engineering integration of existing concepts (self-consistency/contradiction) rather than a fundamental theoretical shift.