📝 Paper Summary
Hallucination suppression
Metrics and evaluation
A benchmarking framework using LLM-based judges (like GPT-4 with Input-Output Prompting) achieves high agreement with human experts in validating the factual correctness of in-car RAG systems.
Core Problem
Ensuring factual correctness in LLM-based in-car conversational systems is critical for safety and user acceptance, but manual validation is impractical due to the high volume of responses and required domain knowledge.
Why it matters:
- Automotive systems must avoid hallucinations (e.g., inventing safety features) to be accepted in production
- Third-party development of components necessitates black-box testing approaches without access to internal model weights
- Manual debugging by engineers is too slow and costly given the extensive domain knowledge required for vehicle manuals
Concrete Example:
When asked about the 'Lane Change Warning light', the system might hallucinate a recommendation to 'brake immediately' (a safety-critical error), whereas the manual only specifies it is an alert. Manual testers might miss this or be too slow to catch it at scale.
Key Novelty
Multi-Method LLM-based Factual Benchmarking Framework
- Applies five distinct LLM reasoning strategies (e.g., Input-Output, Chain-of-Thought, Multi-Persona) to act as automated judges for RAG system outputs
- Evaluates both 'factual consistency' (faithfulness to the manual) and 'factual relevance' (addressing the user's specific question) independently
- Creates a specialized automotive domain dataset with expert-annotated ground truth derived from a BMW SUV owner's manual
Architecture
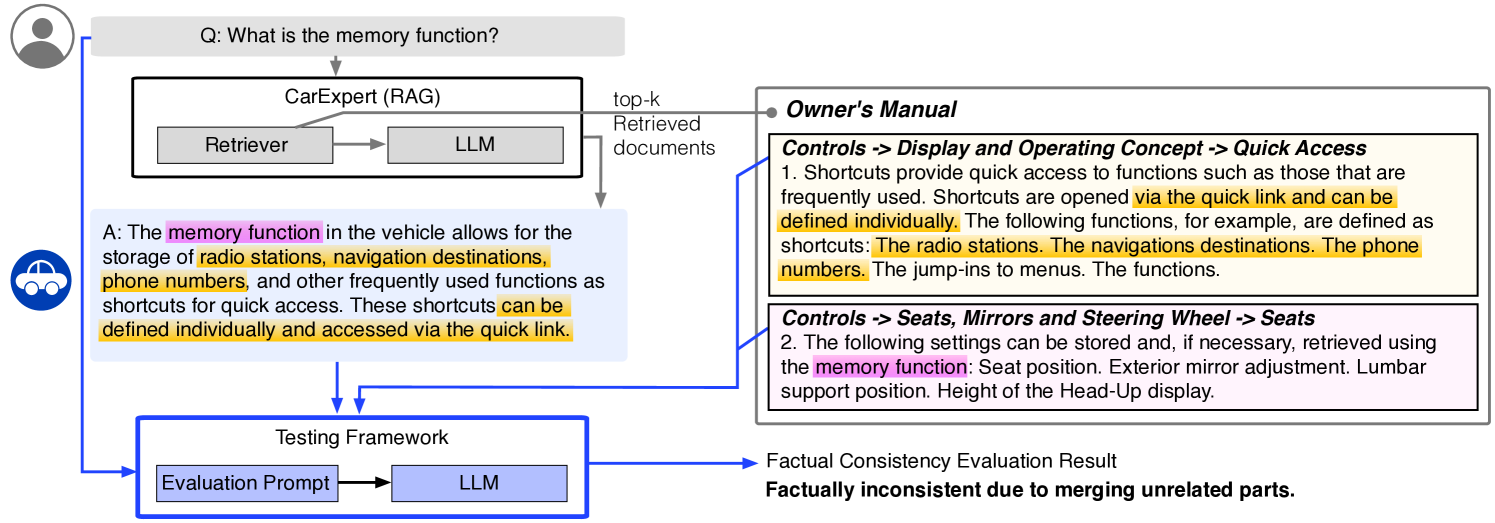
The high-level architecture of the testing framework. It illustrates the flow from User Utterance -> CarExpert (RAG System) -> Testing Framework.
Evaluation Highlights
- GPT-4 with Input-Output (IO) Prompting achieved 92.2% agreement with human experts on factual consistency
- GPT-4 with Round Table (RT) Conference achieved 90.2% consistency agreement and 92.2% relevance agreement
- IO Prompting was the most efficient method, averaging 4.5 seconds per request compared to slower multi-step reasoning methods
Breakthrough Assessment
7/10
Strong practical application demonstrating that LLMs can reliably replace human judges for industrial RAG evaluation. While the methods (CoT, IO) are established, the rigorous application and dataset creation for the automotive domain are valuable contributions.