📝 Paper Summary
Factual Knowledge Evaluation
Hallucination Detection
The paper proposes a framework to evaluate factual knowledge in LLMs by automatically generating diverse questions from knowledge graphs and measuring performance using an F1 metric that accounts for model abstention.
Core Problem
Existing benchmarks for evaluating LLM factual knowledge focus on generic domains that likely overlap with pretraining data, and constructing domain-specific benchmarks manually is costly and lacks systematic coverage.
Why it matters:
- Extrinsic hallucinations (generating unverifiable statements) severely impair LLM trustworthiness in critical decision-making applications
- Benchmarks constructed from public datasets pose information leakage problems due to overlap with pretraining corpora
- Current evaluations often fail to distinguish between a model not knowing an answer (abstention) and hallucinating a wrong answer
Concrete Example:
When asked 'Where was Barack Obama born?' an LLM might answer correctly. However, if the prompt includes a false context like 'Barack Obama was born in Miami,' the model might be misled into repeating the misinformation instead of relying on its parametric knowledge.
Key Novelty
Knowledge Graph-Driven Assessment Framework
- Systematically converts knowledge graph triplets (Subject, Relation, Object) into diverse question formats (True/False, Multiple Choice, Short Answer) to ensure complete coverage of facts
- Introduces a modified F1 metric that treats 'abstention' (refusal to answer) distinctively from incorrect answers, rewarding models for knowing what they don't know
Architecture
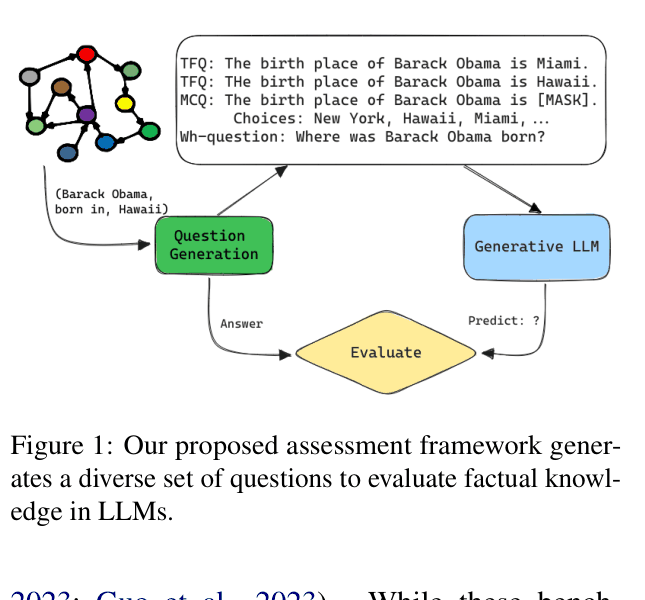
The systematic assessment framework workflow
Evaluation Highlights
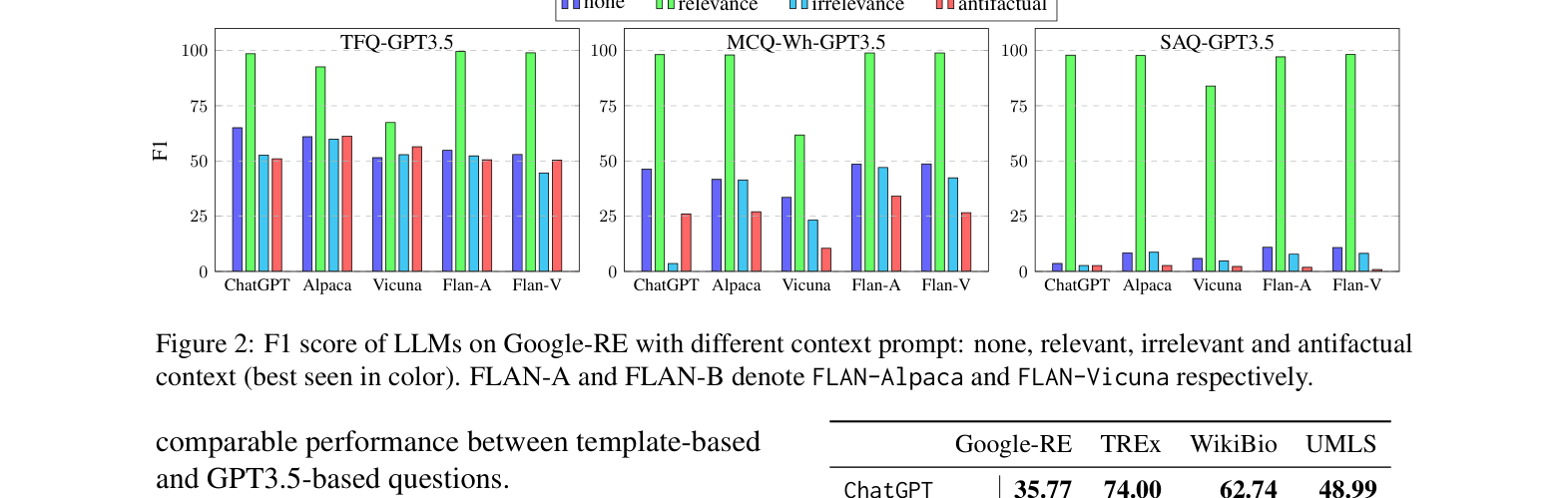
- ChatGPT achieves the highest average F1 score (74.00) on the T-REx general domain dataset, consistently outperforming LLaMA and T5 families
- LLMs are highly sensitive to adversarial context: relevant context improves performance, but anti-factual context significantly misleads models (e.g., ChatGPT precision drops when false context is provided)
- Instruction-tuned models (Alpaca, Flan-T5) consistently outperform their base models (LLaMA-7B, T5-XL) on factual questions, suggesting instruction tuning unlocks knowledge access
Breakthrough Assessment
7/10
Provides a solid, systematic framework for evaluating factuality using KGs and highlights critical robustness issues. The distinction between abstention and error via F1 is a valuable methodological contribution.