📝 Paper Summary
Knowledge update in LLMs
Factual consistency evaluation
WikiFactDiff is a large-scale dataset capturing real-world factual changes between two Wikidata snapshots to evaluate how well language models handle realistic knowledge updates like entity insertion and archival.
Core Problem
Existing knowledge update datasets (like CounterFact and zsRE) rely on unrealistic, randomly generated changes and only cover fact replacement, ignoring common real-world scenarios like new entity insertion or archival.
Why it matters:
- LLMs have a static nature and their knowledge decays over time, requiring updates to remain reliable in domains like healthcare or politics
- Current benchmarks test simple replacements (e.g., changing a capital city randomly), which doesn't reflect how knowledge actually evolves (e.g., a politician leaving office)
- Unrealistic updates in current datasets fail to test whether algorithms maintain global coherence or handle the emergence of completely new entities
Concrete Example:
Current datasets might test updating 'Albert Einstein's field' from 'Physics' to 'Biology', which is unrealistic. WikiFactDiff captures real changes, such as 'Cristiano Ronaldo' moving from 'Juventus F.C.' (obsolete) to 'Al-Nassr' (new), or 'ChatGPT' emerging as a new entity entirely.
Key Novelty
WikiFactDiff: Realistic Temporal Difference Dataset
- Constructs updates by computing the difference between two Wikidata snapshots (Jan 2021 and Feb 2023) to capture actual historical changes rather than synthetic ones
- Categorizes updates into five distinct scenarios beyond just replacement: Archive, AddObject, AddRelation, AddEntity, and ReplaceObject
- Introduces a 'temporal adaptability' pipeline that allows the dataset to be regenerated for any two dates to align with different model training cutoffs
Architecture
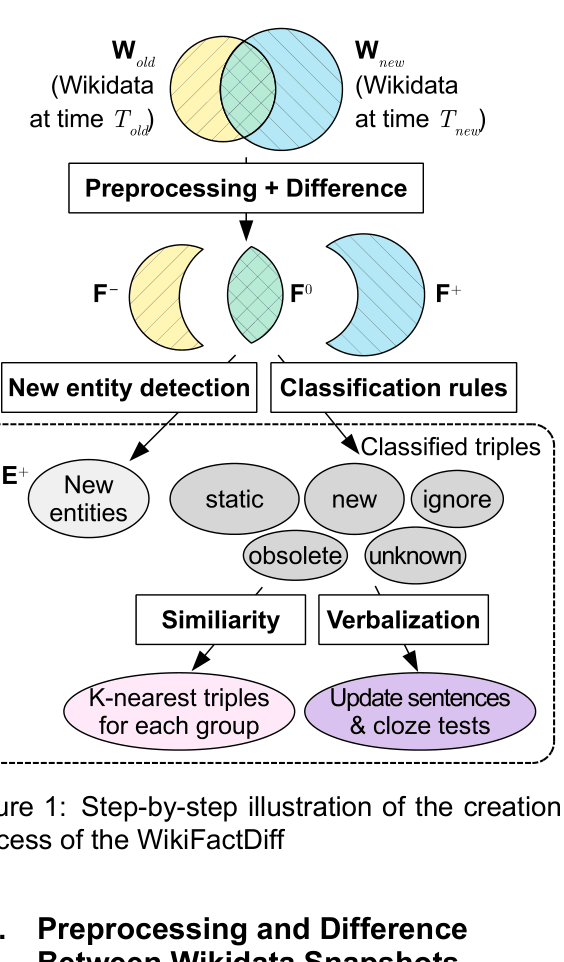
The WikiFactDiff dataset creation pipeline, illustrating how two Wikidata snapshots are processed to generate the final dataset.
Evaluation Highlights
- ROME achieves highest Efficacy-Success (99.7%) and Generalization-Success (98.0%) on the replacement subset, outperforming MEMIT and FT
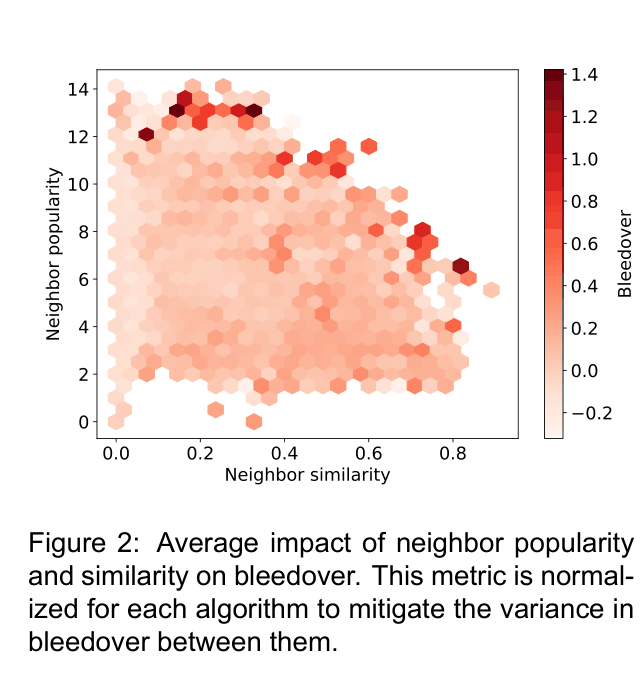
- Fine-tuning (FT) generalizes well (99.5% success) but suffers from massive bleedover (specificity failure), degrading accuracy on neighboring facts
- PROMPT (contextual prompting) is competitive with parameter-update methods (98.9% efficacy) but shows higher bleedover on random neighbors than ROME
Breakthrough Assessment
7/10
Significantly improves the realism of knowledge editing benchmarks by moving beyond synthetic replacements to real-world scenarios like entity insertion. However, it is primarily a dataset contribution rather than a new modeling technique.