📝 Paper Summary
Hallucination suppression
Fact-checking for LLMs
Medical Question Answering
LEAF enhances LLM factuality in medical domains by using an automated fact-checker to guide retrieval during inference and to rank/filter responses for self-training updates.
Core Problem
LLMs frequently generate plausible but factually incorrect content (hallucinations), which is dangerous in high-stakes domains like healthcare where accuracy is critical.
Why it matters:
- Standard RAG methods sometimes degrade performance by retrieving irrelevant noise (as seen in MedRAG results on USMLE)
- Proprietary fact-checking tools cannot be deployed on private medical data due to privacy concerns
- Specialized domains like medicine lack sufficient labeled data for traditional supervised fine-tuning
Concrete Example:
When answering a medical question, a standard LLM might confidently state an incorrect treatment. A standard RAG pipeline might retrieve documents that confuse the model further. LEAF detects the error via fact-checking, retrieves documents specifically targeting the unsupported facts, and prompts the model to correct itself.
Key Novelty
Dual-strategy Factuality Enhancement (Inference-time RAG & Training-time Optimization)
- Fact-Check-Then-RAG: Instead of retrieving before generation, the system generates an answer first, fact-checks it, and only performs retrieval if specific facts are unsupported, using those gaps to guide the search.
- Learning from Fact-Checks: Uses the automated fact-checker as a reward signal for self-training, either by fine-tuning on passing responses (SFT) or using fact-check scores as preference rankings for optimization (SimPO).
Architecture
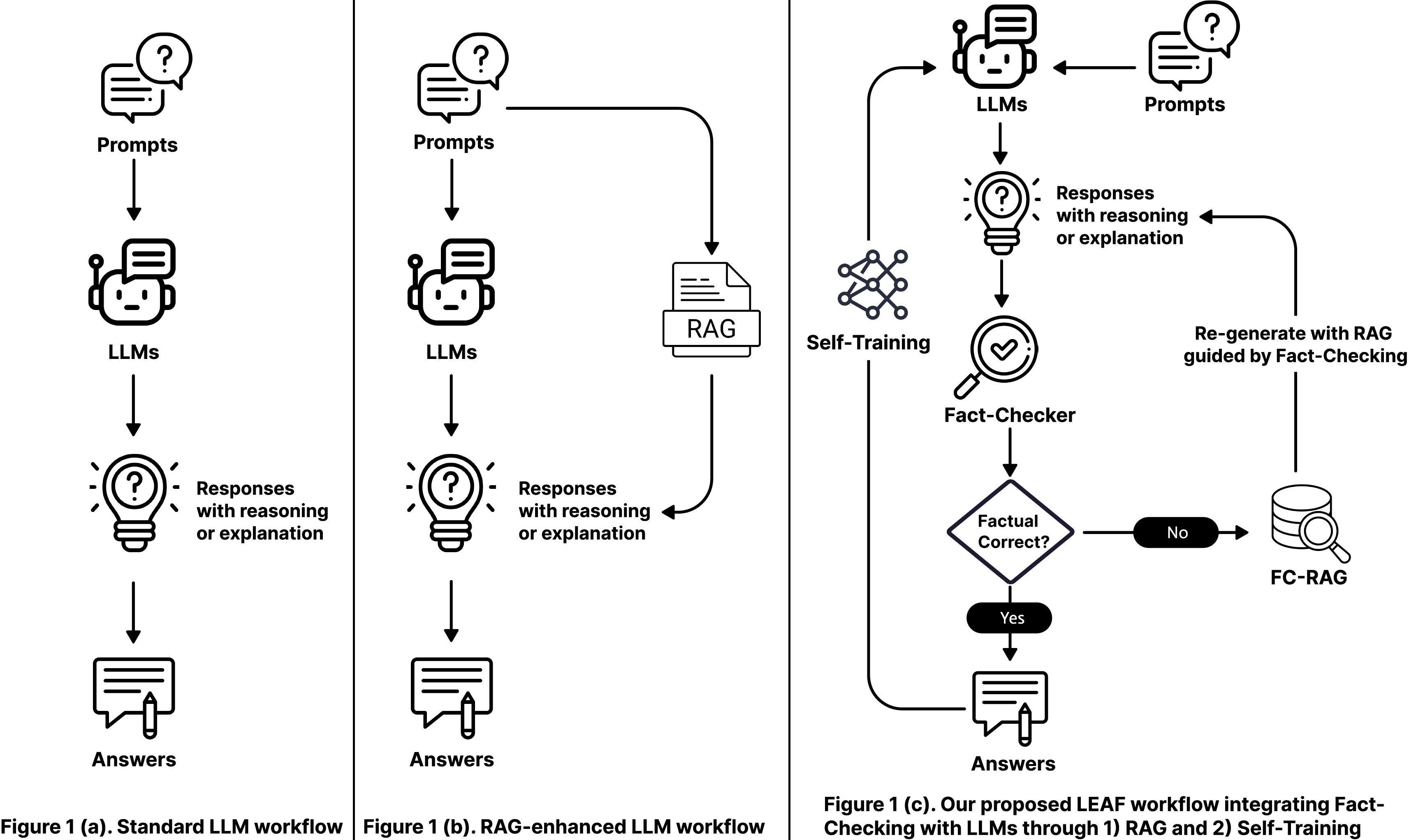
The LEAF workflow comparing conventional LLM generation, standard RAG, and the proposed Fact-Check-Then-RAG and Self-Training pipelines.
Evaluation Highlights
- Fact-Check-Then-RAG improves Llama-3-70B-Instruct by +13.0% on PubMedQA and +4.99% on USMLE compared to the original model.
- Self-training with SimPO using LEAF rankings improves Llama-3-8B-Instruct by +6.80% on PubMedQA and +4.08% on USMLE.
- The proposed Fact-Check-Then-RAG method outperforms standard MedRAG on all five tested medical datasets (USMLE, MMLU-Medical, PubMedQA, BioASQ, MedMCQA).
Breakthrough Assessment
7/10
Solid application of automated fact-checking to close the loop on both inference (RAG) and training (SimPO). While the components (RAG, SimPO, SAFE) exist, integrating them for medical domain adaptation without human labels is a practical advance.