📝 Paper Summary
Multilingual Factual Consistency
Mechanistic Interpretability
Model Editing / Steering
Multilingual LLMs process non-English queries by internally recalling facts in English and translating them; interventions targeting this pipeline significantly improve factual consistency across languages.
Core Problem
Multilingual LLMs often fail to recall facts in non-English languages even when they know the answer in English, leading to cross-lingual factual inconsistencies.
Why it matters:
- Reliability Gap: Non-English users receive significantly higher rates of untruthful answers compared to English users for identical factual queries
- Mechanism Opacity: While prior work suggests English-centric processing, the specific failure modes (recall vs. translation) were not mechanistically linked to inconsistencies
- Inefficient Mitigation: Existing fixes like explicit translation or fine-tuning are computationally expensive or require external calls, whereas internal steering offers a latent capability unlock
Concrete Example:
For the query 'What is the main religion in Thailand?' in a non-English language, the model might fail to output 'Buddhism' (target language) despite internally activating the correct English concept 'Buddhism' at intermediate layers.
Key Novelty
Two-Stage Multilingual Factual Recall Pipeline & Steering
- Mechanistically characterizes the recall pipeline as: (1) English-centric retrieval in middle layers, followed by (2) Translation to target language in late layers
- Identifies two distinct failure modes: 'Translation Failure' (correct English concept found, wrong output) and 'Recall Failure' (English concept never found)
- Proposes two language-agnostic inference-time interventions: a 'Translation Difference Vector' to fix conversion errors and an 'In-Context Learning Vector' to fix retrieval errors
Architecture
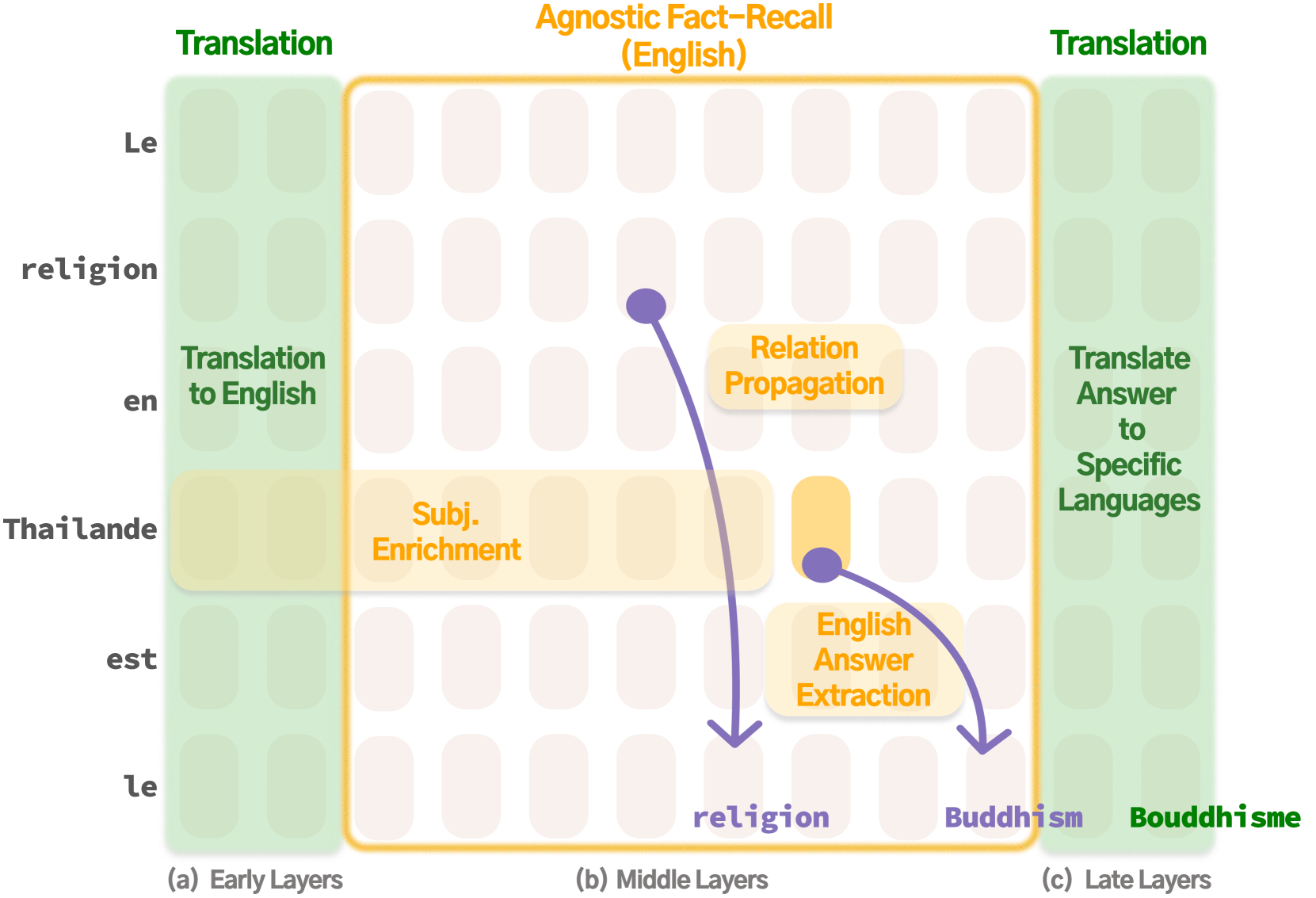
Conceptual diagram of the hypothesized multilingual factual recall pipeline and the two intervention points.
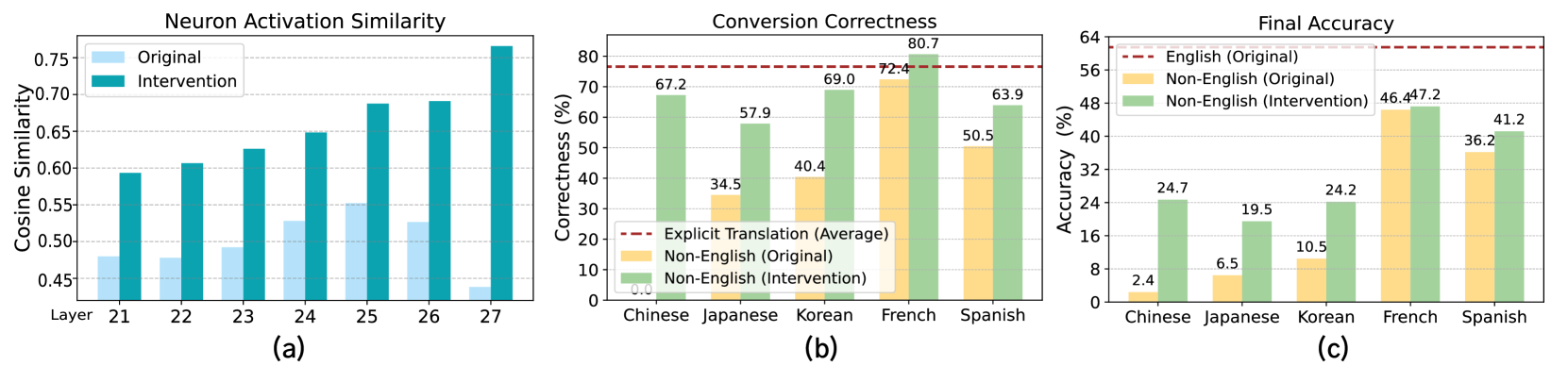
Evaluation Highlights
- +37.6 percentage points accuracy gain in the lowest-performing language (Thai) using combined interventions
- +19.04 percentage points average accuracy gain across all six evaluated languages (English, Chinese, Japanese, Korean, French, Spanish)
- Translation intervention raises 'conversion correctness' (translating internal English concept to output) from 39.56% to 67.74%
Breakthrough Assessment
8/10
Strong mechanistic evidence for the English-centric hypothesis and a highly effective, lightweight intervention that unlocks significant latent multilingual performance without retraining.