📝 Paper Summary
Knowledge Editing
Multilingual LLMs
LU-LAFNs enables simultaneous multilingual knowledge editing by identifying and updating shared 'language-agnostic' neurons that encode the same fact across different languages.
Core Problem
Existing Multilingual Knowledge Editing (MKE) methods often treat languages separately or fail to model the shared semantic connections of facts, leading to conflicts where updating one language degrades performance in others.
Why it matters:
- Large Language Models (LLMs) are increasingly deployed in multilingual settings, requiring synchronized updates of facts across all supported languages.
- Ignoring cross-lingual connections causes 'knowledge conflicts' where updates fail to propagate correctly or damage the model's general abilities.
- Directly applying monolingual editing methods (like ROME or MEMIT) to multilingual contexts often degrades edit reliability and locality.
Concrete Example:
When adapting monolingual editors like MEMIT to update a fact in multiple languages, the edit performance often degrades (e.g., success rate drops significantly compared to single-language editing) because the method does not account for the shared internal representation of that fact across languages.
Key Novelty
Locating and Updating Language-Agnostic Factual Neurons (LU-LAFNs)
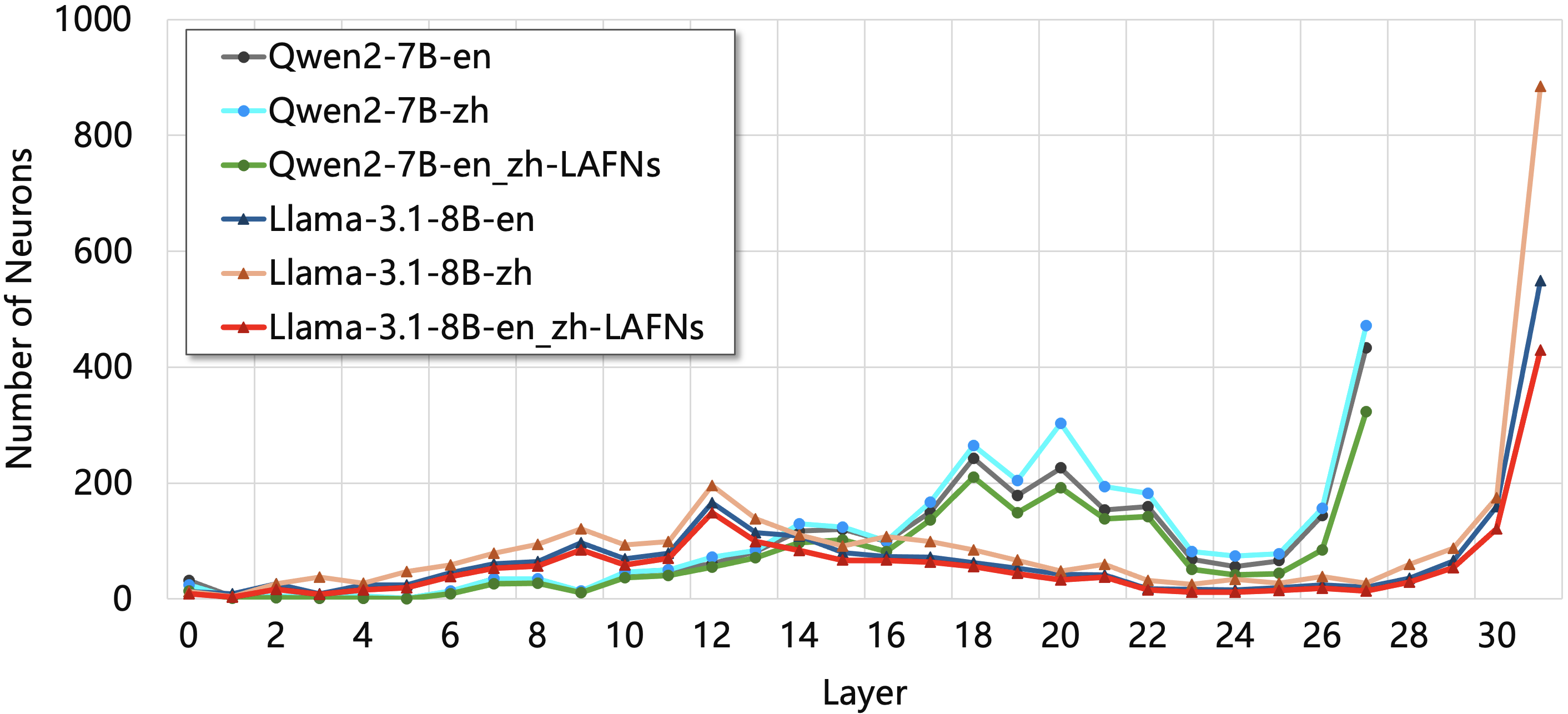
- First, the paper discovers 'Language-Agnostic Factual Neurons' (LAFNs)—a shared set of neurons in Feed-Forward Networks (FFNs) that activate for the same fact regardless of the input language.
- Second, it proposes a method to locate these specific shared neurons using paraphrased inputs and then optimize update values to modify them.
- Finally, instead of permanently altering weights, it caches these update values and retrieves them during inference when the relevant subject is detected.
Architecture
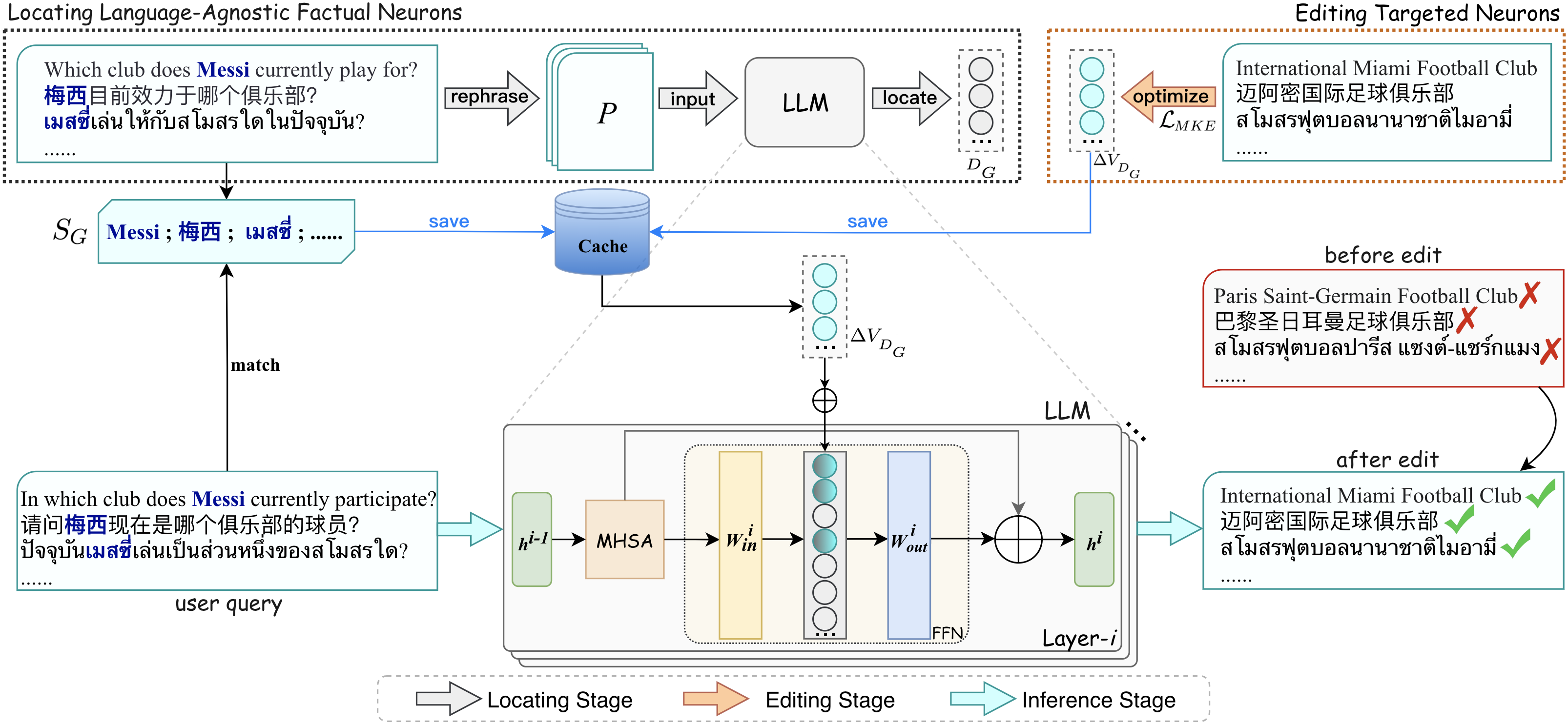
The overall framework of LU-LAFNs.
Evaluation Highlights
- Outperforms state-of-the-art MKE methods on the Bi-ZsRE benchmark, achieving the highest reliability and generality scores.
- Achieves superior performance on the MzsRE benchmark across multiple language pairs (e.g., English-Chinese, English-French), significantly reducing knowledge conflicts.
- Demonstrates that editing shared LAFNs is more effective than editing language-specific neurons, validating the existence of cross-lingual knowledge sharing in LLMs.
Breakthrough Assessment
7/10
Solid contribution identifying a specific biological-inspired mechanism (shared neurons) for multilingual editing. The caching mechanism is practical, though the reliance on exact subject matching for retrieval might limit robustness in the wild.