📝 Paper Summary
Hallucination suppression
Preference-based alignment
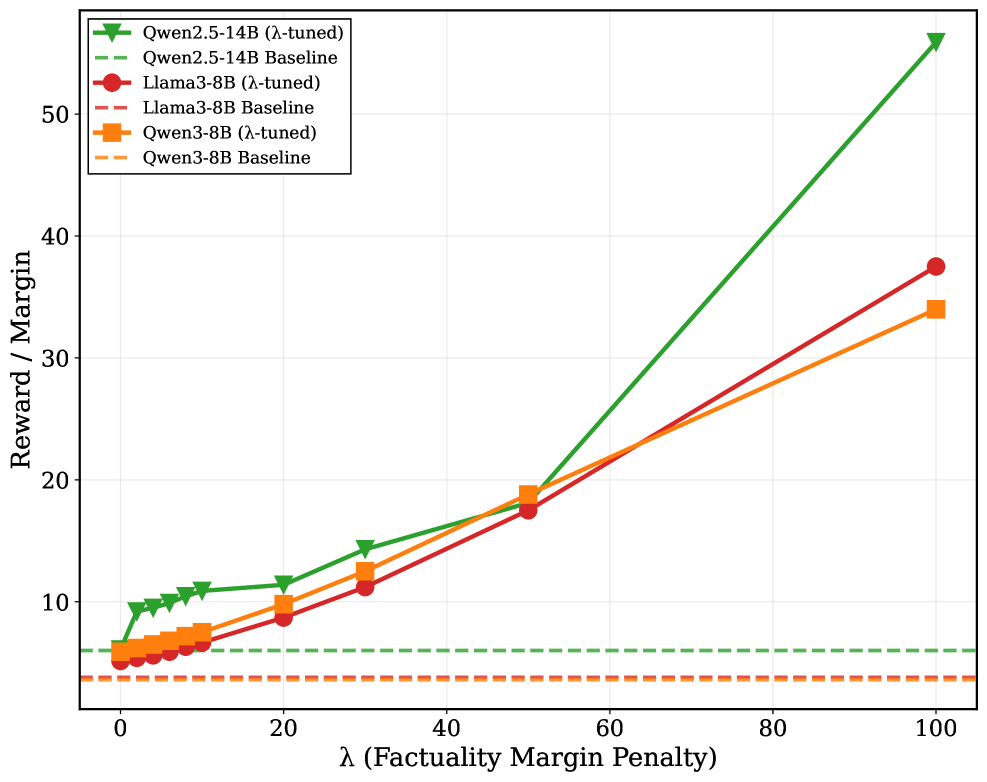
F-DPO modifies the Direct Preference Optimization objective to prioritize factual correctness over fluency by flipping mislabeled preference pairs and adding a margin penalty when the chosen response is hallucinated.
Core Problem
Standard preference alignment methods like DPO reinforce hallucinations because annotators often prefer fluent, confident, but factually incorrect responses over concise, accurate ones.
Why it matters:
- High-stakes domains (medicine, law) require strict adherence to truth, but standard alignment prioritizes style
- Existing solutions require complex auxiliary reward models, multi-stage training, or fine-grained token-level supervision
- Preference datasets contain inherent noise where human or model judges systematically misrank hallucinated responses as better than factual ones
Concrete Example:
When asked 'What is the capital of Australia?', annotators may prefer the incorrect but confident 'The capital is Sydney, its largest city' over the correct but simple 'Canberra'. Standard DPO reinforces the Sydney answer; F-DPO detects the factuality gap and flips the preference label.
Key Novelty
Factuality-aware Direct Preference Optimization (F-DPO)
- Augment preference pairs with binary factuality labels (factual vs. hallucinated) derived from an automated judge
- Apply 'Label Flipping': If a hallucinated response is preferred over a factual one, swap the preference direction so the model learns to choose the factual response
- Apply 'Factuality-Conditioned Margin': Add a penalty term to the loss function that pushes the model to distinguish factuality more aggressively than standard preferences
Architecture
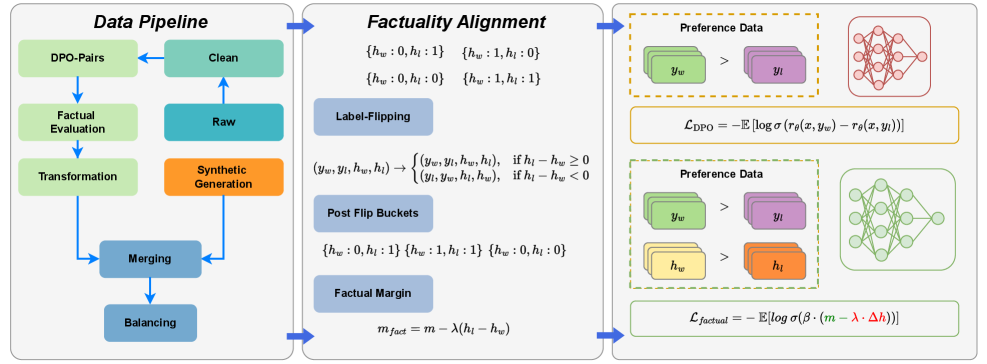
Overview of F-DPO method contrasting it with standard DPO.
Evaluation Highlights
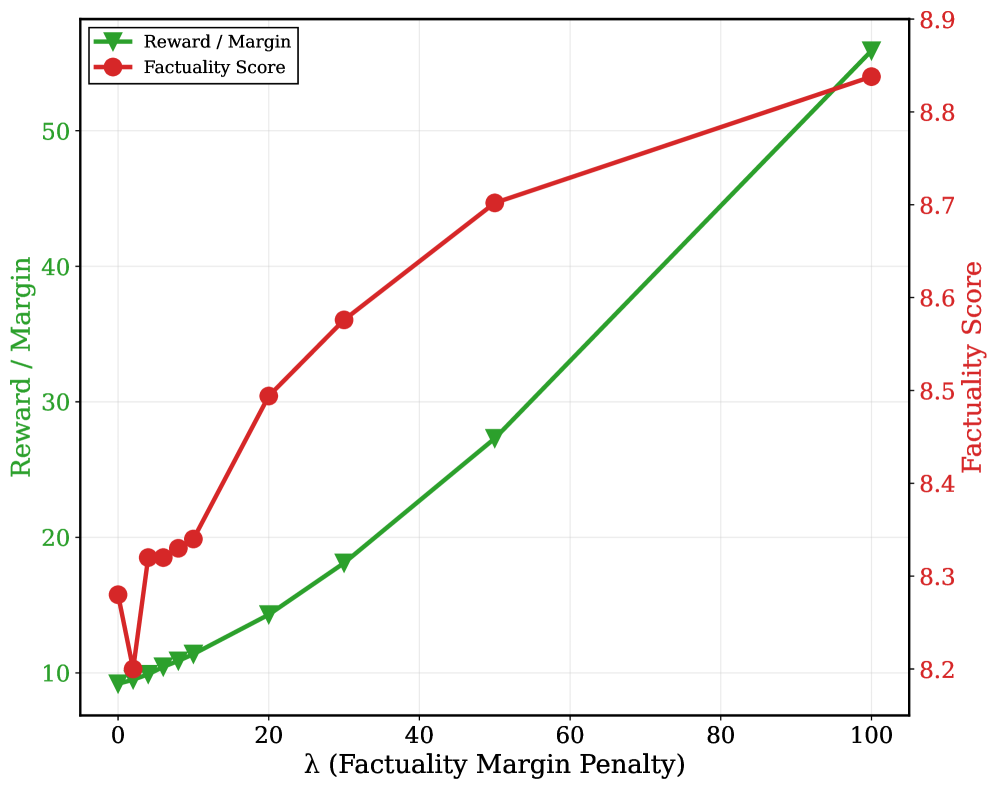
- Reduces hallucination rate by 5x on Qwen3-8B (from 0.424 to 0.084) compared to the base model
- Achieves 0.008 hallucination rate on Qwen2.5-14B, nearly an order of magnitude improvement over the base model
- Improves TruthfulQA MC2 accuracy by +49% (0.357 to 0.531) on Qwen2.5-14B, showing strong out-of-distribution generalization
Breakthrough Assessment
8/10
Simple yet highly effective modification to DPO that solves a critical alignment failure mode (style-over-substance) without auxiliary reward models or complex pipelines.