📝 Paper Summary
Reinforcement Learning for Reasoning
Hallucination Suppression
FSPO mitigates hallucinations in reasoning models by verifying intermediate steps against evidence and adjusting token-level RL advantages, rather than relying solely on final-answer correctness.
Core Problem
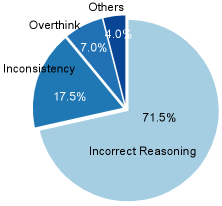
Outcome-based RL fine-tuning for reasoning tasks exacerbates hallucinations because models can learn incorrect intermediate reasoning steps that coincidentally lead to correct answers (spurious local optima) or generate high-entropy confident errors.
Why it matters:
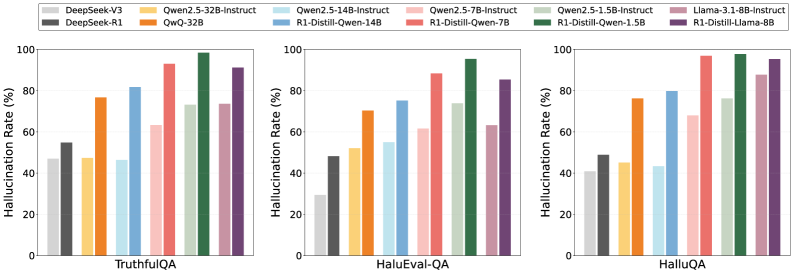
- Models trained with standard RL (like DeepSeek-R1) show significantly higher rates of fabricated statements across benchmarks like TruthfulQA and HaluEval
- Optimizing only for the final answer creates sparse rewards and high-variance gradients, making it difficult for models to learn faithful reasoning patterns
- Unreliable reasoning chains undermine trust, even if the final answer is correct, as the model may justify its output with false claims
Concrete Example:
In a HaluEval-QA case, DeepSeek-R1 answers correctly but generates a reasoning chain with fabricated facts, whereas the base model DeepSeek-V3 does not. The RL-tuned model is 'confidently wrong' in its reasoning path because it was only penalized for the final outcome.
Key Novelty
Factuality-aware Step-wise Policy Optimization (FSPO)
- Integrates an automated verifier into the RL loop that checks each generated reasoning sentence against external evidence (e.g., Wikipedia)
- Modifies the standard advantage function by re-weighting token-level advantages based on step-wise factuality scores (entailed vs. contradicted)
- Provides dense feedback signals to the policy, ensuring that valid reasoning steps are rewarded even if the final answer is wrong, and fabricated steps are penalized even if the final answer is right
Architecture
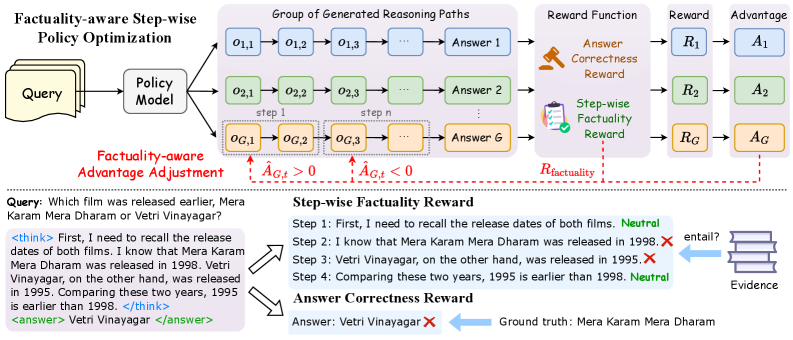
Overview of the Factuality-aware Step-wise Policy Optimization (FSPO) framework.
Evaluation Highlights
- FSPO significantly reduces hallucination rates on TruthfulQA compared to standard RL baselines using Qwen2.5 and Llama-3.1 models
- Improves mathematical reasoning accuracy on challenging benchmarks while maintaining higher factuality than purely outcome-driven RL methods
- Enhances the reliability of intermediate reasoning steps without compromising the fluency or quality of the generated text
Breakthrough Assessment
8/10
Addresses a critical and timely failure mode of current reasoning models (hallucination induction via RL) with a theoretically grounded and effective solution. The step-wise verification approach directly tackles the sparsity of outcome-based rewards.